
上一篇
python 初始化函数
在Python中,初始化函数通常是类的构造函数__init__,当我们创建一个类的新实例时,__init__方法会自动调用,这个方法通常用于设置新创建的对象的初始状态。

下面我将展示如何在Python中使用初始化函数,以及如何利用网络请求库如requests来获取互联网上的最新内容。
步骤1: 导入必要的库
我们需要导入requests库,这是一个常用的Python HTTP客户端库,用于发送HTTP请求,如果你还没有安装这个库,可以使用pip进行安装:
pip install requests
步骤2: 定义一个类
接下来,我们定义一个名为ContentFetcher的类,它将包含我们的初始化函数和获取内容的方法。
import requests
class ContentFetcher:
def __init__(self, url):
self.url = url
self.content = None
# 其他方法将会在这里添加
步骤3: 实现初始化函数
在__init__方法中,我们接收一个URL参数,并将其存储在实例变量self.url中,我们还初始化了一个名为self.content的变量,用于存储从网络上获取的内容。
步骤4: 添加获取内容的方法
我们将添加一个名为fetch_content的方法,该方法将使用requests库从指定的URL获取内容,并将其存储在self.content中。
class ContentFetcher:
def __init__(self, url):
self.url = url
self.content = None
def fetch_content(self):
response = requests.get(self.url)
if response.status_code == 200:
self.content = response.text
else:
print(f"Failed to fetch content. Status code: {response.status_code}")
步骤5: 使用类
现在,我们可以创建一个ContentFetcher的实例,并使用它来获取网络上的内容。
if __name__ == "__main__":
# 初始化ContentFetcher对象
fetcher = ContentFetcher("https://example.com")
# 获取内容
fetcher.fetch_content()
# 输出获取到的内容
if fetcher.content:
print(fetcher.content)
else:
print("No content fetched.")
这样,我们就创建了一个简单的类,它可以从一个给定的URL获取内容,当然,实际的网络请求可能会更复杂,可能包括处理cookies、headers、重试逻辑等,但这个例子展示了基本的初始化函数的使用和网络请求的基础。
注意事项
确保你有权限访问目标URL,否则你可能会遇到权限错误或被拒绝。
考虑到网络请求可能会失败,你应该在代码中加入适当的错误处理逻辑。
当处理大量数据或长时间运行的请求时,应该考虑使用异步编程技术来提高性能。
通过上述步骤,你可以使用Python初始化函数和requests库来从互联网上获取最新内容,记得在实际使用时,根据需求调整代码,并添加更多的错误处理和功能。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/332558.html
相关文章
-

python3(python3完全兼容Python2吗)(python3.0完全兼容python2.0吗)
-
python批量运行cmd_python 之多主机批量执行命令(python批量执行多个py文件)
-

python 客户端 服务器6_Pythonbinarymemcached客户端连接Memcached(Python)
-
python 客户端 服务器_Pythonbinarymemcached客户端连接Memcached(Python)
-
客户端服务器python_Python-binary-memcached客户端连接Memcached(Python)
-
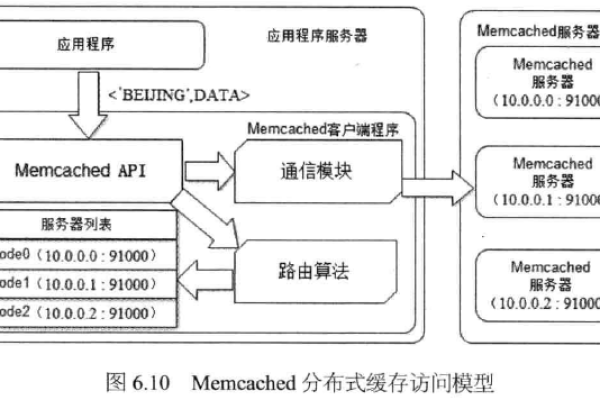
python客户端与服务器端_Python-binary-memcached客户端连接Memcached(Python)
-
python服务器和多个客户端_Python-binary-memcached客户端连接Memcached(Python)
-
python客户端服务器端_Python-binary-memcached客户端连接Memcached(Python)








