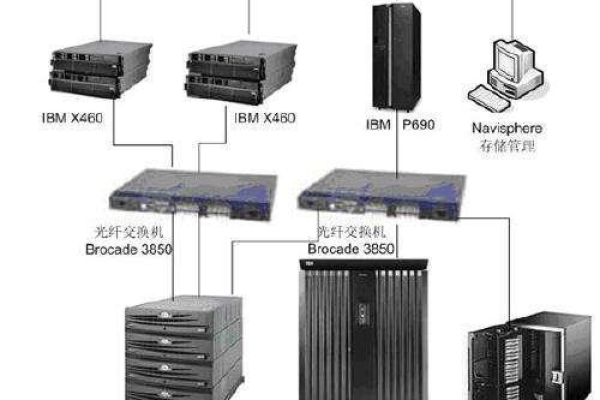
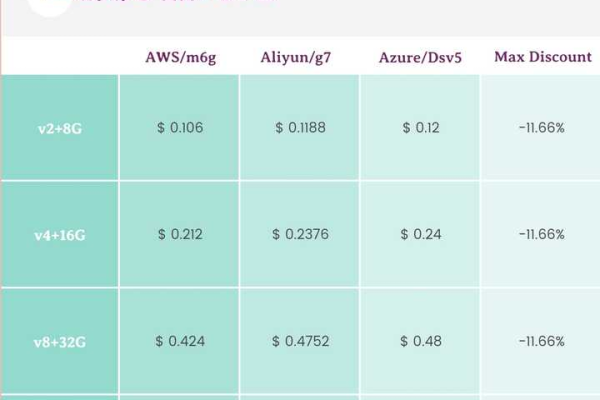
帝都云组服务器_服务器组

1、帝都云组服务器
帝都云组服务器是一种基于云计算技术的服务,旨在为用户提供高效、可靠的服务器资源,通过采用虚拟化技术,将物理服务器资源分割成多个虚拟服务器,以满足不同用户的业务需求,这种服务模式不仅提高了资源的利用率,还降低了用户的运营成本。
2、服务器配置方法
在配置帝都云组服务器时,用户需要选择合适的操作系统和软件版本,可以选择CentOS 7 64bit作为操作系统,并安装n2n 3.0.0版本,为了避免兼容性问题,建议服务端和客户端使用相同版本的软件,用户还可以选择RPM安装或编译安装两种方式进行软件部署。
3、网络连接检查与问题排查
当服务器无法连接时,首先需要检查网络连接是否正常,可以通过ping命令测试服务器IP地址是否可达,或者使用telnet命令测试服务器端口是否开放,如果网络连接存在问题,可以进一步排查硬件故障、软件配置错误等问题。

4、安全组规则配置
为了确保服务器的安全性,用户可以配置安全组规则来控制入方向和出方向的流量,在配置安全组规则时,需要设置源IP地址、端口号等信息,还需要确保实例内对应的端口也已经放通,以便安全组规则能够对实例生效。
5、弹性云服务器列表管理
用户可以进入弹性云服务器列表页面进行服务器的管理,在管理控制台中,选择相应的区域和项目后,可以查看到所有的弹性云服务器,通过单击“操作”列中的选项,可以进行服务器的启动、停止、重启等操作。
6、服务器合并与迁移

在某些情况下,可能需要将多个服务器合并为一个服务器以优化资源利用率,在进行服务器合并时,需要考虑数据迁移、应用程序兼容性等因素,还需要通知用户合并的时间和影响范围,以便用户做好相应的准备。
下面介绍一些相关的FAQs:
Q1: 如何选择合适的服务器配置?
Q2: 如何排查服务器无法连接的问题?
正确答案是:首先检查网络连接是否正常,可以通过ping命令测试服务器IP地址是否可达,或者使用telnet命令测试服务器端口是否开放,如果网络连接存在问题,可以进一步排查硬件故障、软件配置错误等问题。

帝都云组服务器提供了一种高效、可靠的服务器资源服务,通过了解其配置方法、网络连接检查与问题排查、安全组规则配置以及弹性云服务器列表管理等方面的知识,用户可以更好地利用这种服务来满足自己的业务需求,了解服务器合并与迁移的相关知识也有助于优化资源利用率和管理服务器资源。