上一篇
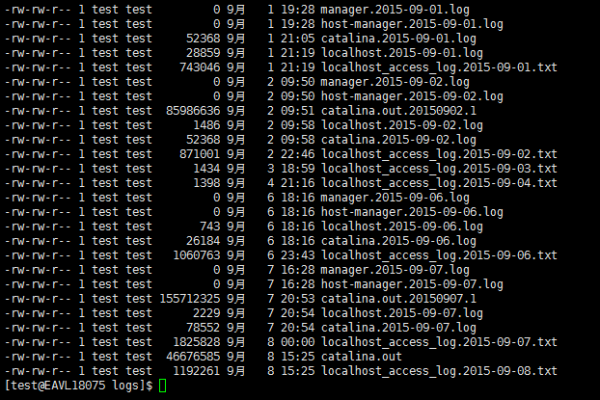
awk命令 统计日志
awk命令可以用于统计日志,例如统计某个时间段内的访问量、请求次数等。具体用法需要根据日志格式和需求进行调整。
在Linux系统中,awk是一种文本处理工具,它可以对文本文件进行分析和处理,awk命令的基本语法是:awk [选项] ‘pattern { action }’ file,pattern是一个正则表达式,用于匹配文本中的特定模式;action是对匹配到的模式执行的操作;file是要处理的文件名。
本文将介绍如何在Linux中使用awk命令进行日志分析和处理。
awk的基本用法
1、打印指定列
awk可以很容易地打印指定列的内容,假设我们有一个名为log.txt的日志文件,我们想要打印第2列和第4列的内容,可以使用以下命令:
awk '{print $2, $4}' log.txt
2、使用分隔符
默认情况下,awk使用空格作为字段分隔符,我们可以使用其他字符作为分隔符,假设我们有一个名为log.txt的日志文件,字段之间用逗号分隔,我们可以使用以下命令:
awk F, '{print $2, $4}' log.txt
3、过滤行
我们可以使用条件语句来过滤不需要的行,假设我们想要过滤掉log.txt文件中第1列值小于10的行,可以使用以下命令:
awk '$1 >= 10' log.txt
awk的高阶用法
1、计算统计信息
awk可以用于计算各种统计信息,如平均值、总和等,假设我们有一个名为data.txt的数据文件,我们想要计算第3列的平均值,可以使用以下命令:
awk '{sum += $3; count++} END {print sum / count}' data.txt
2、使用数组和函数
awk支持数组和函数,这使得我们可以编写更复杂的脚本,假设我们有一个名为data.txt的数据文件,我们想要计算第3列的最大值和最小值,可以使用以下命令:
awk '{arr[$3] = $3} END {max = max(arr); min = min(arr)} END {print "Max: " max, "Min: " min}' data.txt
3、使用循环和条件语句
awk支持循环和条件语句,这使得我们可以编写更复杂的脚本,假设我们有一个名为data.txt的数据文件,我们想要打印出所有第3列值大于10的行,可以使用以下命令:
awk '$3 > 10' data.txt
awk的实际应用案例
1、分析日志文件
在Linux系统中,日志文件是非常重要的资源,我们可以使用awk命令来分析日志文件,找出潜在的问题,假设我们有一个名为app.log的应用程序日志文件,我们想要找出所有错误级别的日志行,可以使用以下命令:
awk '/ERROR/' app.log
2、提取数据字段
在处理数据时,我们经常需要提取特定的字段,我们可以使用awk命令来实现这一目标,假设我们有一个名为data.csv的CSV格式数据文件,我们想要提取第2列和第4列的值,可以使用以下命令:
awk F, '{print $2, $4}' data.csv > output.txt
相关问题与解答
1、问题:如何使用awk命令删除文件中的空行?
解答:可以使用以下命令删除文件中的空行:awk '!/^$/' file,这个命令会打印出所有非空行,要直接修改文件,可以使用重定向操作:awk '!/^$/' file > output.txt,这将把非空行写入output.txt文件。
2、问题:如何使用awk命令替换文件中的某个字符串?
解答:可以使用以下命令替换文件中的某个字符串:awk '{gsub(/old_string/, new_string); print}' file > output.txt,这个命令会打印出替换后的行,要直接修改文件,可以使用重定向操作:awk '{gsub(/old_string/, new_string); print}' file > output.txt,这将把替换后的行写入output.txt文件。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/315842.html