上一篇
BP神经网络在训练过程中如何实现收敛?
BP神经网络通过梯度下降法和误差反向传播算法进行训练,逐步调整权重以最小化损失函数。
BP神经网络的收敛性分析

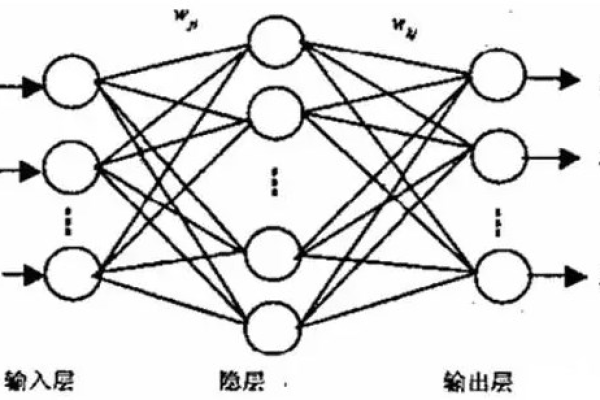
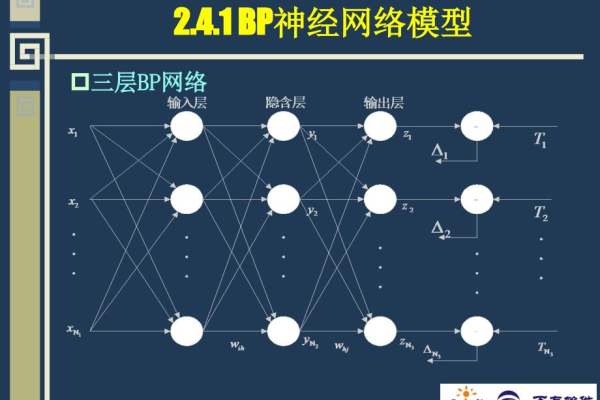
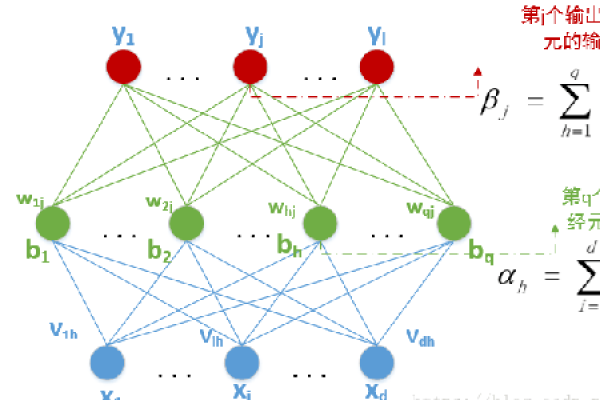
BP神经网络(Back Propagation Neural Network)是一种多层前馈神经网络,因其在解决复杂非线性问题中的有效性而闻名,它由输入层、隐含层和输出层组成,其中隐含层可以有多个,BP神经网络的工作原理是通过误差反向传播算法来调整网络权重,该算法首先将输入数据正向传播至输出层,计算输出与期望输出之间的误差,将误差反向传播回网络,并根据误差值调整权重,这个过程不断重复,直到误差达到预设的阈值或训练次数达到预设值。
一、BP神经网络收敛性理论
梯度下降法
BP神经网络使用梯度下降法来最小化损失函数,梯度下降法通过沿着负梯度方向更新权值,逐步接近局部极小值,每次迭代中,网络的权重都会根据以下公式进行更新:
$$
Delta w = -eta frac{partial E}{partial w}
$$
$eta$是学习率,$E$是误差函数,$w$是权重。
误差反向传播算法
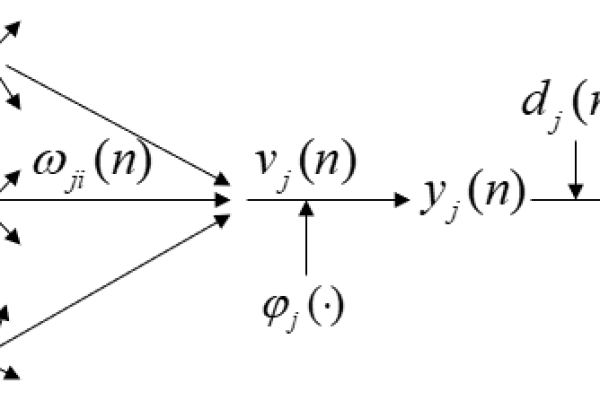
误差反向传播算法计算损失函数的梯度,并将其反向传播到网络中,通过更新权值来减少损失函数,网络逐步收敛到局部极小值,误差反向传播的具体步骤如下:
前向传播:输入数据通过各层神经元传播,得到预测输出。
误差计算:计算预测输出与实际输出之间的误差。
误差传递:从输出层向前传播,逐层计算各神经元对总误差的贡献。
权重更新:根据计算出的误差,调整各神经元的权重。
二、影响BP神经网络收敛的因素
学习率
学习率是影响BP神经网络收敛速度和稳定性的关键因素,较大的学习率可能会导致网络不稳定,而较小的学习率则可能导致收敛速度缓慢,学习率的选择需要通过实验进行调整。
动量因子
动量因子用于平滑权值更新,防止网络陷入局部极小值,动量因子的加入可以加速收敛并减少震荡。
激活函数
非线性激活函数(如ReLU、Sigmoid)引入非线性,使网络能够学习复杂关系,不同的激活函数对网络的收敛性和性能有不同的影响。
数据集
训练数据集的质量和数量对网络的收敛性和泛化能力有重要影响,一个好的训练数据集应该具有代表性、多样性,并且尽量无噪声。
网络结构
网络的深度和宽度也会影响收敛性,过深的网络可能导致梯度消失问题,而过浅的网络可能无法有效表达问题的复杂性。
三、提高BP神经网络收敛速度的方法
调整学习率
动态调整学习率是一种常见的方法,使用学习率衰减策略,在训练过程中逐渐降低学习率,可以提高收敛速度和精度。
使用动量法
动量法通过引入动量项来平滑权值更新,可以加快收敛速度并减少震荡。
选择适当的优化算法
除了标准的梯度下降法,还可以选择其他优化算法,如Adam、RMSprop等,这些算法在更新权值时考虑了更多的因素,可以加速收敛。
正则化
正则化技术(如L1、L2正则化)可以防止过拟合,提高网络的泛化能力。
数据预处理
对数据进行归一化、去噪等预处理操作,可以提高网络的训练效果和收敛速度。
四、案例分析
以一个简单的两层BP神经网络为例,其中输入层有2个节点,隐含层有3个节点,输出层有1个节点,网络的损失函数为均方误差(MSE),以下是Python代码示例:
import numpy as np
定义网络参数
input_nodes = 2
hidden_nodes = 3
output_nodes = 1
learning_rate = 0.1
momentum_factor = 0.9
随机初始化权值
weights_ih = np.random.randn(hidden_nodes, input_nodes)
weights_ho = np.random.randn(output_nodes, hidden_nodes)
训练数据
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
训练网络
for epoch in range(1000):
# 前向传播
hidden_activations = np.dot(X, weights_ih)
hidden_outputs = np.maximum(0, hidden_activations) # ReLU激活函数
output_activations = np.dot(hidden_outputs, weights_ho)
output = output_activations
# 计算误差
error = y output
# 反向传播
output_gradient = -2 * error
hidden_gradient = np.dot(output_gradient, weights_ho.T) * (hidden_activations > 0) # ReLU激活函数的梯度
# 更新权值
weights_ho -= learning_rate * np.dot(output_gradient, hidden_outputs.T) + momentum_factor * weights_ho
weights_ih -= learning_rate * np.dot(hidden_gradient, X.T) + momentum_factor * weights_ih
# 评估网络
if epoch % 100 == 0:
print(f'Epoch {epoch}, Error: {np.mean(np.abs(error))}')在这个例子中,我们使用ReLU激活函数和动量法来训练一个简单的BP神经网络,通过调整学习率和动量因子,可以观察网络的收敛情况。
五、归纳与展望
BP神经网络作为一种强大的机器学习工具,广泛应用于模式识别、预测和分类等领域,其收敛速度和稳定性仍然是研究的重点,通过调整学习率、使用动量法、选择适当的优化算法和正则化技术,可以有效提高BP神经网络的收敛速度和性能,随着深度学习领域的不断发展,我们可以期待看到更多高效、实用的神经网络模型和应用。
到此,以上就是小编对于“bp神经网络 收敛”的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位朋友在评论区讨论,给我留言。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:https://www.xixizhuji.com/fuzhu/310454.html