
上一篇
html 如何 缓存
HTML 缓存是一种提高网页加载速度和性能的技术,它可以减少对服务器的请求次数,从而降低网络带宽的消耗,下面是关于 HTML 缓存的一些详细内容:

1、浏览器缓存:
浏览器缓存是最常见的缓存方式之一,当用户访问一个网页时,浏览器会将该网页的相关文件(如 HTML、CSS、JavaScript 等)存储在本地缓存中,以便下次访问时可以直接从缓存中获取,而不需要再次向服务器发送请求。
浏览器缓存分为强缓存和协商缓存两种类型。
强缓存: 浏览器首先检查本地缓存是否已过期,如果没有过期则直接使用缓存的资源,不会向服务器发送请求。
协商缓存: 如果本地缓存已过期或不存在,浏览器会向服务器发送请求,并携带一些标识信息(如 LastModified 和 ETag),服务器根据这些信息判断资源是否有更新,然后返回相应的状态码和数据。
2、HTTP 缓存头:
HTTP 响应头中包含了一些用于控制缓存的字段,可以通过设置这些字段来配置浏览器的缓存行为。
常见的 HTTP 缓存头有:
CacheControl: 用于指定缓存策略,包括 nocache、nostore、maxage 等选项。
Expires: 指定资源的过期时间。
LastModified: 表示资源的最后修改时间。
ETag: 用于标识资源的唯一性,可以与服务器进行比较来判断资源是否有更新。
3、Service Workers:
Service Workers 是一种在浏览器后台运行的脚本,可以拦截网络请求并进行自定义处理,通过使用 Service Workers,可以实现更灵活的缓存策略和离线功能。
Service Workers 可以监听网络请求,并根据一定的规则来决定是否从缓存中返回资源,或者向服务器发送请求。
4、优化建议:
根据具体情况选择适当的缓存策略,避免过度缓存或频繁更新导致的问题。
对于不经常变动的资源(如图片、样式表等),可以使用较长的缓存时间;对于经常更新的资源(如 JavaScript 文件、API 接口等),可以使用较短的缓存时间或动态生成的文件名。
使用版本号或其他标识来区分不同版本的资源,以便及时更新用户端的缓存。
以上是关于 HTML 缓存的一些详细介绍和建议,可以根据具体需求选择合适的缓存策略来提高网页的性能和用户体验。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/308321.html
相关文章
-

关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
-
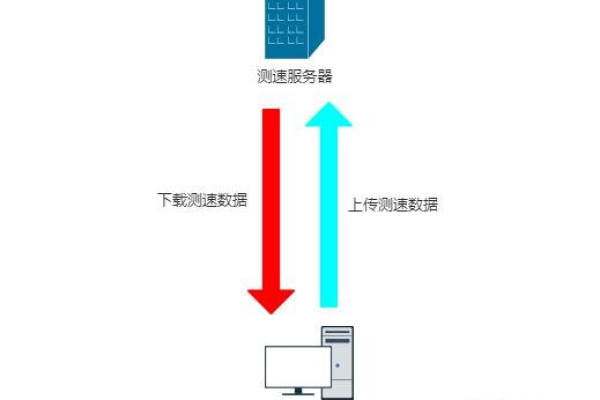
本地缓存 VS 服务器缓存:如何提高网页加载速度? (本地缓存 服务器缓存)
-

nginx静态缓存(nginx缓存清理缓存)(nginx 静态缓存)
-
关于HTML表格列间距怎么调这个问题,一个直接且相关的疑问句标题可以是,如何调整HTML表格的列间距?。这个问题直接询问了如何改变HTML表格中列与列之间的间距,是用户在寻求具体操作方法时可能会提出的明确问题。
-
在html中如何让图片居中 html如何把图片居中,图片居中怎么设置html
-

HTML HTML如何在HTML body中编码引号
-

HTML HTML按钮与HTML提交按钮的区别
-

在线制作html5页面,制作音乐排行榜HTML5「html制作音乐网站」
-
html网页编程手机软件,能打开html的手机软件「html做的网页手机可以打开吗」








