
上一篇
如何导入.html文件
在计算机编程和网页开发中,HTML(超文本标记语言)是一种用于创建网页的标准标记语言,HTML文件包含了网页的结构和内容,通过浏览器可以查看和解析这些文件,在本教程中,我们将介绍如何导入HTML文件。

1、我们需要了解HTML文件的基本结构,一个基本的HTML文件包含以下几个部分:
<!DOCTYPE html>:声明文档类型为HTML5。
<html>:根元素,包含了整个HTML文档的内容。
<head>:包含了文档的元数据,如标题、字符集等。
<body>:包含了可见的页面内容,如文本、图片、链接等。
2、创建一个HTML文件
要创建一个HTML文件,你可以使用任何文本编辑器,如Notepad++、Sublime Text、Visual Studio Code等,将以下代码复制到一个文本文件中,并将其保存为index.html:
<!DOCTYPE html>
<html>
<head>
<title>我的第一个HTML文件</title>
</head>
<body>
<h1>欢迎来到我的网站!</h1>
<p>这是一个使用HTML编写的简单网页。</p>
</body>
</html>
3、导入HTML文件
要将HTML文件导入到其他程序或项目中,你需要将其内容读取为字符串,然后根据需要进行解析和处理,以下是一些常见的方法:
使用Python的内置函数open()读取文件内容:
with open('index.html', 'r', encoding='utf8') as file:
content = file.read()
print(content)
使用Node.js的fs模块读取文件内容:
const fs = require('fs');
const content = fs.readFileSync('index.html', 'utf8');
console.log(content);
使用Java的FileReader类读取文件内容:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class ReadHtmlFile {
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("index.html"))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
4、解析HTML文件内容
将HTML文件内容读取为字符串后,你可以根据需要进行解析和处理,你可以使用正则表达式提取特定的标签和属性,或者使用HTML解析库(如BeautifulSoup、Jsoup等)来解析整个HTML文档的结构,以下是使用Python的BeautifulSoup库解析HTML文件的示例:
from bs4 import BeautifulSoup
import re
with open('index.html', 'r', encoding='utf8') as file:
content = file.read()
soup = BeautifulSoup(content, 'html.parser')
title = soup.title.string
print("网页标题:", title)
h1 = soup.find('h1')
print("一级标题:", h1.text)
p = soup.find_all('p')[0] # 获取第一个段落标签
print("段落内容:", p.text)
5、归纳
在本教程中,我们介绍了如何创建一个基本的HTML文件,以及如何使用不同的编程语言和方法导入和解析HTML文件,通过学习这些知识,你可以开始创建自己的网页,并掌握更多关于HTML和网页开发的技能。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/306789.html
相关文章
-

关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
-
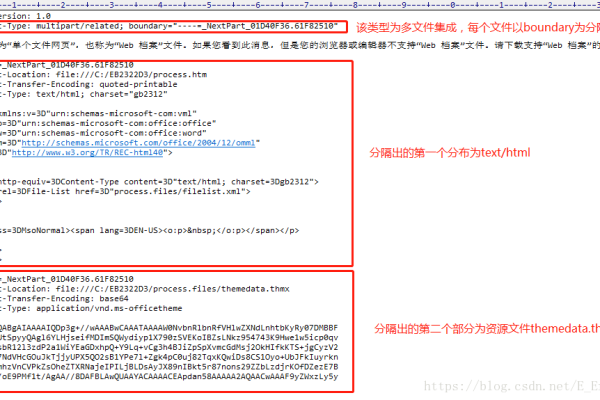
如何编辑html文件,如何建立HTML文件
-
eclipse如何导入html文件
-
Chrome 如何导出证书?,详解 Chrome 浏览器证书导出步骤与注意事项,,Chrome 浏览器简介,证书重要性,导出证书前准备,确认网站使用 HTTPS,打开开发者工具,导出证书步骤,查看证书信息,复制证书到文件,导入证书方法,打开Chrome设置页面,选择管理证书,完成证书导入,常见问题解答,无法查看证书信息,导出证书失败,导入证书无效,归纳与未来趋势,Chrome 安全功能发展趋势,用户需关注网络安全措施
-
Chrome 如何导出证书?,详解 Chrome 浏览器证书导出步骤与注意事项,,Chrome 浏览器简介,证书重要性,导出证书前准备,确认网站使用 HTTPS,打开开发者工具,导出证书步骤,查看证书信息,复制证书到文件,导入证书方法,打开Chrome设置页面,选择管理证书,完成证书导入,常见问题解答,无法查看证书信息,导出证书失败,导入证书无效,归纳与未来趋势,Chrome 安全功能发展趋势,用户需关注网络安全措施
-
HTML 使用Python将文本文件转换为HTML文件
-
墨刀如何导出html文件
-

HTML 如何使网站运行index.html文件








