
上一篇
html如何解析标签
HTML(HyperText Markup Language,超文本标记语言)是一种用于创建网页的标准标记语言,它使用一系列标签来定义网页的结构和内容,在HTML中,标签是由尖括号包围的关键字,例如<p>、<h1>等,标签通常是成对出现的,第一个标签是开始标签,第二个标签是结束标签,在开始标签和结束标签之间的内容被称为元素。

解析HTML标签的过程主要包括以下几个步骤:
1、字符流处理:需要将HTML文档转换为字符流,以便对其进行逐字符的处理,这可以通过读取文件或者从网络接收数据来实现。
2、词法分析:词法分析器(也称为扫描器或分词器)负责将字符流分解为一个个的标记(Token),在这个过程中,词法分析器会根据HTML规范识别出各种标签、属性和文本内容。
3、语法分析:语法分析器(也称为解析器)负责根据HTML规范检查词法分析器生成的标记序列是否合法,如果序列合法,语法分析器会将其转换为一棵抽象语法树(AST),这棵树表示了HTML文档的结构。
4、构建DOM树:遍历抽象语法树,根据每个节点的属性和子节点信息构建一个DOM(Document Object Model,文档对象模型)树,DOM树是一个层次结构,表示了HTML文档的元素和属性。
5、渲染:浏览器会根据DOM树渲染网页,这个过程包括计算样式、布局、绘制等步骤。
下面是一个简单的HTML文档示例:
<!DOCTYPE html>
<html>
<head>
<title>我的第一个HTML页面</title>
</head>
<body>
<h1>欢迎来到我的网站</h1>
<p>这是一个段落。</p>
<a href="https://www.example.com">点击这里访问示例网站</a>
</body>
</html>
对于这个HTML文档,我们可以按照上述步骤进行解析:
1、字符流处理:读取HTML文档的内容。
2、词法分析:将字符流分解为以下标记:DOCTYPE, html, head, title, /head, body, h1, p, a, href, /a, /body, /html。
3、语法分析:检查标记序列是否合法,在这个例子中,标记序列是合法的,因为它遵循了HTML规范。
4、构建DOM树:遍历抽象语法树,构建DOM树,DOM树的结构如下:
document
├── head
│ └── title
└── body
├── h1
├── p
└── a
5、渲染:浏览器根据DOM树渲染网页,在这个例子中,渲染后的网页包含一个标题、一个段落和一个链接。
归纳一下,解析HTML标签的过程涉及到字符流处理、词法分析、语法分析、构建DOM树和渲染等步骤,通过这些步骤,浏览器可以正确地解析HTML文档,并将其渲染为可视化的网页。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/306292.html
相关文章
-

关于AngularJS中的ngbindhtml指令,一个原创的疑问句标题可以是,,如何在AngularJS中使用ngbindhtml指令安全地绑定并显示HTML内容?,清晰地表达了想要了解如何在AngularJS中利用ngbindhtml指令来绑定并显示HTML内容,同时强调了安全地这一关键点,表明提问者对于数据绑定的安全性有所关注。
-
在html中如何让图片居中 html如何把图片居中,图片居中怎么设置html
-

HTML HTML如何在HTML body中编码引号
-
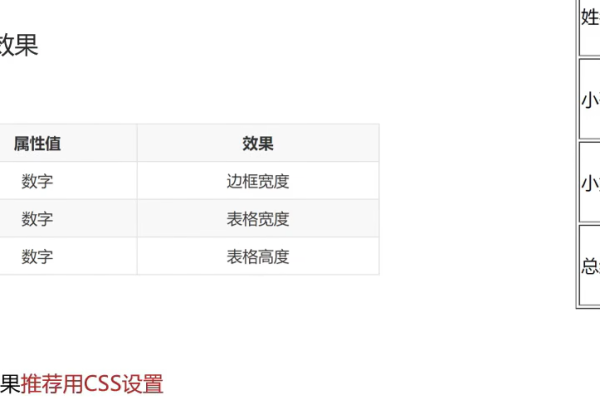
关于HTML表格列间距怎么调这个问题,一个直接且相关的疑问句标题可以是,如何调整HTML表格的列间距?。这个问题直接询问了如何改变HTML表格中列与列之间的间距,是用户在寻求具体操作方法时可能会提出的明确问题。
-

HTML HTML按钮与HTML提交按钮的区别
-

在线制作html5页面,制作音乐排行榜HTML5「html制作音乐网站」
-
html网页编程手机软件,能打开html的手机软件「html做的网页手机可以打开吗」
-
html怎么强制换行显示,在HTML中什么标记可以强制文本换行(html强制换段标记)








