网站建设工作室能否提供完善的售后服务,提供高质量网站建设服务

网站建设工作室能否提供完善的售后服务和高质量的网站建设服务,取决于其专业能力、服务态度和客户反馈。选择时应考察其案例、口碑和服务承诺。
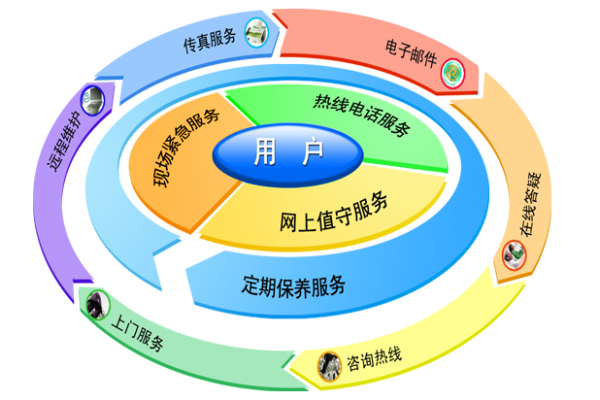
网站建设工作室的售后服务与高质量服务
完善的售后服务
一个优秀的网站建设工作室,不仅在建设过程中提供专业的服务,更在项目完成后,为客户提供持续的售后支持,以下是一些可能的售后服务:
1. 技术支持与维护
网站在运营过程中可能会遇到各种技术问题,如服务器故障、功能失效等,优秀的网站建设工作室会提供技术支持与维护服务,帮助客户解决这些问题。
2. 网站更新与升级
随着互联网的发展,网站需要不断更新和升级以适应新的技术和用户需求,优秀的网站建设工作室会提供网站更新与升级服务,确保客户的网站始终保持最新状态。

3. 培训与指导
为了让客户更好地使用和管理网站,优秀的网站建设工作室会提供培训与指导服务,教授客户如何使用网站的后台管理系统,以及如何进行日常的网站管理。
高质量的网站建设服务
优秀的网站建设工作室,会在项目的每个阶段都提供高质量的服务,以下是一些可能的服务:
1. 需求分析
在项目开始时,工作室会与客户进行深入的需求分析,了解客户的需求和期望,以便制定出最适合客户的网站建设方案。

2. 设计与开发
在设计和开发阶段,工作室会根据需求分析的结果,设计出美观、易用的网站界面,并进行高质量的代码开发,确保网站的稳定性和性能。
3. 测试与优化
在网站上线前,工作室会进行严格的测试,找出并修复可能的问题,也会对网站进行优化,提高其加载速度和搜索引擎排名。
4. 上线与推广

在网站上线后,工作室会帮助客户进行网站的推广,吸引更多的用户访问。
| 服务阶段 | 服务内容 |
| 需求分析 | 深入了解客户需求,制定网站建设方案 |
| 设计与开发 | 设计美观、易用的网站界面,进行高质量的代码开发 |
| 测试与优化 | 进行严格的测试,找出并修复可能的问题,对网站进行优化 |
| 上线与推广 | 帮助客户进行网站的推广 |
优秀的网站建设工作室能够提供完善的售后服务和高质量的网站建设服务,帮助客户建立并运营成功的网站。








热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01