上一篇
机器学习算法,机器学习是什么
机器学习是一种人工智能领域的技术,通过让计算机系统从数据中学习并改进性能,无需显式编程。它涉及算法和统计模型,使机器能够预测、识别模式并进行决策。
机器学习算法与机器学习概述
什么是机器学习?
机器学习是人工智能的一个分支,它赋予计算机系统通过数据和经验自我学习的能力,而无需明确编程,简而言之,它是一种使计算机能够“学习”的技术,以便从数据中提取模式并做出决策或预测。
机器学习的主要类型
监督学习
在监督学习中,模型通过标记好的训练数据进行学习,每个训练样本都有一个与之对应的输出标签,学习的目标是构建一个模型,该模型可以预测未知数据的输出。
无监督学习
无监督学习涉及未标记的数据,算法试图自行发现数据中的结构,主要用途包括聚类、密度估计和降维。
强化学习
强化学习是一个反馈和决策的过程,其中机器通过与环境的互动来学习,目标是最大化累积奖励。
半监督学习和自学习
这些是介于监督学习和无监督学习之间的混合类型,它们利用大量的未标记数据和一些标记数据进行学习。
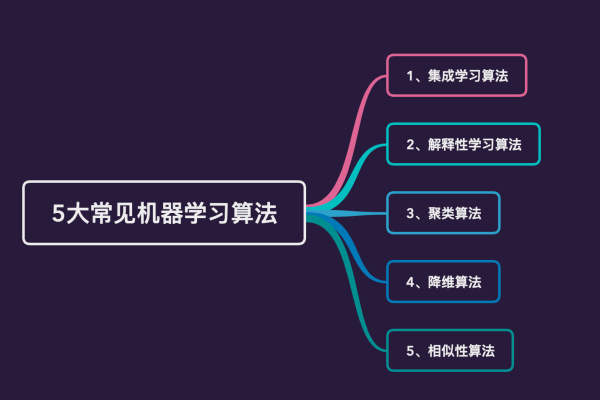
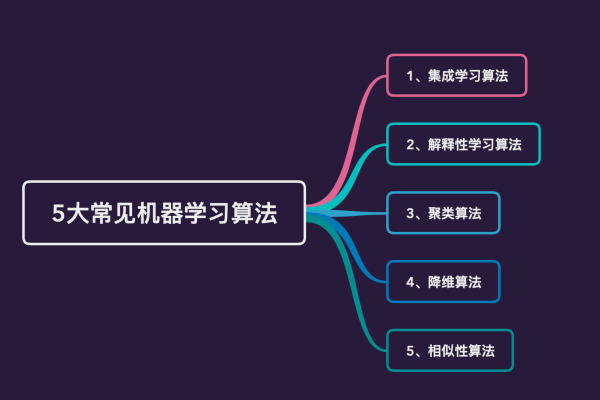
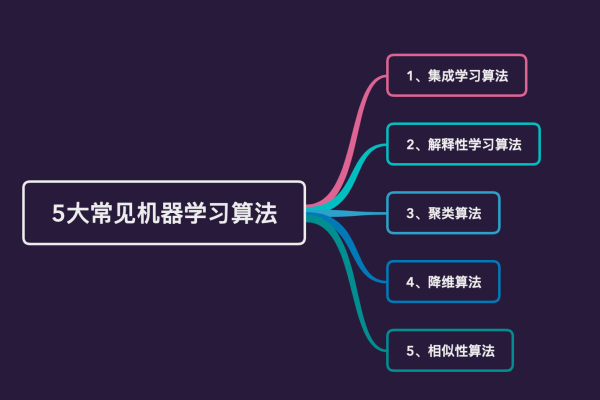
常见的机器学习算法
回归分析
用于预测连续值的输出,如房价预测。
分类算法
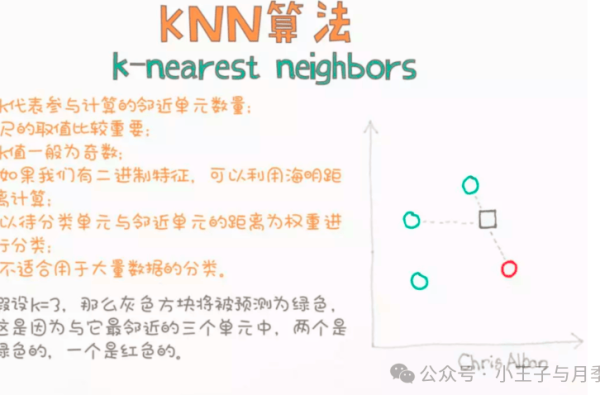
例如决策树、支持向量机(SVM)、K最近邻(KNN),主要用于预测离散标签。
聚类算法
如K均值、层次聚类,用于将数据分为不同的组或“簇”。
神经网络
深度学习中使用的算法,能够处理复杂的模式识别问题。
集成方法
如随机森林和梯度提升机(GBM),它们结合多个模型来提高预测性能。
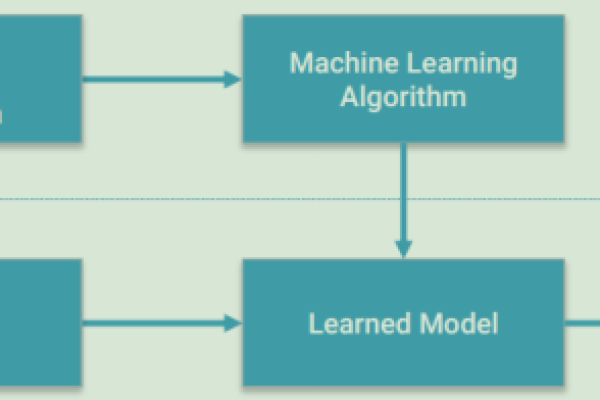
机器学习流程
1、定义问题:确定你想要机器学习帮你解决的问题。
2、数据收集:收集相关的数据。
3、数据处理:清理、选择和转换数据以供使用。
4、选择模型:选择一个或几个机器学习模型。
5、训练模型:使用训练数据来训练你的模型。
6、评估模型:用测试数据评估模型的性能。
7、参数调整:根据需要调整模型参数以提高性能。
8、部署模型:将模型部署到生产环境以解决实际问题。
相关问题与解答
Q1: 机器学习与统计学有何不同?
A1: 机器学习与统计学都涉及从数据中提取信息并进行预测,但机器学习更侧重于通过算法从大量数据中"学习"并改进其性能,而统计学则更关注于从理论和数学角度对数据进行建模和推断。
Q2: 为什么需要对数据进行预处理?
A2: 数据预处理是为了改善模型的性能,原始数据可能包含噪声、缺失值、异常值或不一致性,这些都会影响机器学习模型的准确性,预处理步骤包括清洗、规范化、归一化和特征选择等,以确保数据质量并为模型提供准确的输入。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/304942.html