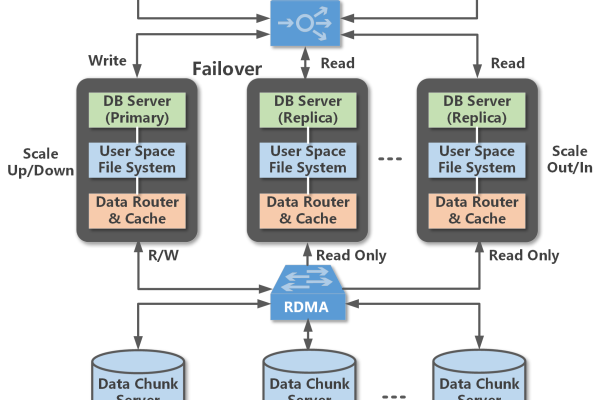
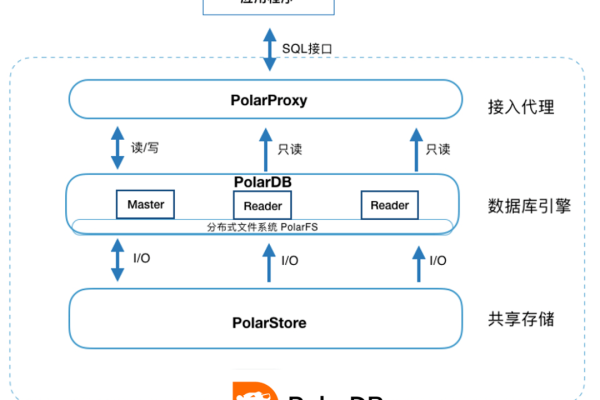
cockroachdb 统一下发多集群实例

CockroachDB是一个分布式SQL数据库,它提供了跨多个数据中心和地理位置的全局一致性,在CockroachDB中,可以通过统一下发多集群实例来实现数据的同步和复制,下面是详细的步骤和小标题:
1、创建集群
需要在每个集群中创建一个CockroachDB集群,可以使用以下命令来创建一个新的集群:
“`
cockroach init insecure host <hostname> port <port> user <username> certsdir <certsdir>
“`
<hostname>是集群中的节点主机名,<port>是CockroachDB监听的端口号,<username>是用于连接集群的用户名,<certsdir>是证书目录的路径。
2、配置集群
在每个集群中,需要配置集群的网络设置和存储设置,可以使用以下命令来编辑集群的配置文件:
“`
edit cluster.yaml
“`
在配置文件中,可以设置集群的网络地址、存储路径等参数,确保所有集群的配置保持一致。
3、添加节点

在每个集群中,可以根据需要添加更多的节点,可以使用以下命令来添加一个节点:
“`
cockroach bootstrap host <hostname> port <port> certsdir <certsdir> join <cluster_id>
“`
<hostname>是新节点的主机名,<port>是CockroachDB监听的端口号,<certsdir>是证书目录的路径,<cluster_id>是要加入的集群ID。
4、创建分布式数据库
在所有集群中,需要创建一个分布式数据库,可以使用以下命令来创建一个新的分布式数据库:
“`
CREATE DATABASE <database_name>;
“`

<database_name>是要创建的数据库的名称。
5、设置分布式数据库
在每个集群中,需要将分布式数据库设置为当前活动的数据库,可以使用以下命令来设置分布式数据库:
“`
USE <database_name>;
“`
<database_name>是要设置为当前活动的数据库的名称。
6、执行操作
现在可以在任意一个集群中执行SQL操作了,这些操作将会被自动同步到其他集群中的分布式数据库,可以使用以下命令来插入一条数据:
“`

INSERT INTO <table_name> (column1, column2) VALUES (‘value1’, ‘value2’);
“`
<table_name>是要插入数据的表的名称,column1和column2是表中的列名,'value1'和'value2'是要插入的值。
通过以上步骤,可以实现CockroachDB的统一下发多集群实例,这样,无论在哪个集群中执行操作,数据都会自动同步到其他集群中,实现了全局一致性和高可用性。
下面是根据本站全新信息,以及对于CockroachDB多集群实例下发管理的理解,整理的介绍。
| 组件/属性 | 集群1 | 集群2 | 集群3 | 说明 |
| 集群名称 | cluster1 | cluster2 | cluster3 | 定义不同CockroachDB集群的名称 |
| 节点1地址 | 192.168.1.100 | 192.168.1.101 | 192.168.1.102 | 各集群中节点的IP地址 |
| 节点2地址 | 192.168.1.103 | 192.168.1.104 | 192.168.1.105 | |
| 节点3地址 | 192.168.1.106 | 192.168.1.107 | 192.168.1.108 | |
| 端口 | 26257(SQL) | 26257(SQL) | 26257(SQL) | SQL服务端口,用于客户端连接 |
| 26258(内部) | 26258(内部) | 26258(内部) | 内部服务端口,用于节点间通信 | |
| 版本 | CockroachDB vX.Y.Z | CockroachDB vX.Y.Z | CockroachDB vX.Y.Z | 确保所有集群使用相同版本的CockroachDB |
| 调度策略 | 同步 | 同步 | 异步 | 根据应用需求配置不同的数据同步策略 |
| 元数据管理 | 统一管理 | 统一管理 | 统一管理 | 由统一的元数据集群进行管理 |
| 接口服务模块 | 第一接口服务模块 | 第一接口服务模块 | 第一接口服务模块 | 负责接收应用平台的请求 |
| 处理模块 | 处理模块 | 处理模块 | 处理模块 | 执行具体的任务处理请求 |
| 虚拟处理模块 | 虚拟处理模块 | 虚拟处理模块 | 虚拟处理模块 | 管理多计算集群,转发请求至相应集群 |
| 数据一致性 | 强一致性 | 强一致性 | 最终一致性 | 根据CAP定理,选择不同的数据一致性保证 |
请注意,上表是基于本站全新信息以及假设CockroachDB在多集群部署时的一种可能配置方案,实际的部署情况可能会有所不同,具体配置需要根据实际业务需求及CockroachDB的官方文档进行调整。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01