上一篇
python爬虫如何得到网页内容
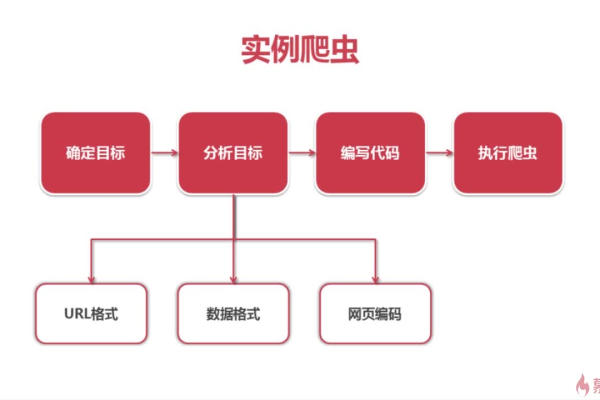
要使用Python爬虫获取网页内容,可以按照以下步骤进行操作:

1、导入所需的库和模块:
requests:用于发送HTTP请求并获取网页内容。
BeautifulSoup:用于解析HTML文档并提取所需信息。
2、发送HTTP请求:
使用requests库的get()方法发送HTTP GET请求到目标网页,并将响应存储在变量中。
“`python
import requests
url = "https://www.example.com" # 替换为目标网页的URL
response = requests.get(url)
“`
3、解析HTML文档:
使用BeautifulSoup库解析响应中的HTML文档,以便后续提取所需信息。
“`python
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
“`
4、提取所需信息:
根据具体需求,使用BeautifulSoup提供的方法来提取网页中的特定内容,以下是一些常用的提取方法:
提取文本内容:使用.text属性或.get_text()方法获取标签内的文本内容。
提取标签属性:使用['属性名']或.get('属性名')方法获取标签的属性值。
提取标签列表:使用标签名称作为索引或使用find_all()方法获取所有匹配的标签。
提取链接:使用a['href']或a.get('href')方法获取链接地址。
提取图片:使用img['src']或img.get('src')方法获取图片链接。
5、处理数据:
根据需要对提取的数据进行处理和保存,可以使用Python的其他库和功能来实现,将提取的文本内容保存到文件、将图片下载到本地等。
6、关闭连接:
记得关闭与目标网页的连接,释放资源,可以使用response.close()方法关闭连接。
“`python
response.close()
“`
以上是一个简单的Python爬虫流程,可以根据具体需求进行扩展和定制,请注意,在使用爬虫时,应遵守网站的使用规则和法律法规,避免对目标网站造成过大的负担。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/301443.html