
上一篇
pandas 逐行读取csv
在Python中,pandas库是一个强大的数据处理库,它可以帮助我们轻松地处理各种数据格式,如CSV、Excel等,在本教程中,我们将学习如何使用pandas逐行读取CSV文件。

我们需要安装pandas库,如果你还没有安装,可以使用以下命令进行安装:
pip install pandas
接下来,我们将分以下几个步骤进行讲解:
1、导入pandas库
2、使用read_csv()函数读取CSV文件
3、逐行读取CSV文件
4、关闭已打开的文件
1. 导入pandas库
在开始之前,我们需要导入pandas库,可以使用以下代码进行导入:
import pandas as pd
2. 使用read_csv()函数读取CSV文件
要读取CSV文件,我们可以使用pandas库中的read_csv()函数,这个函数接受一个参数,即CSV文件的路径,如果我们有一个名为data.csv的CSV文件,可以使用以下代码读取它:
df = pd.read_csv('data.csv')
这将读取整个CSV文件并将其存储在一个名为df的DataFrame对象中,DataFrame是pandas中用于存储和操作表格数据的主要数据结构。
3. 逐行读取CSV文件
我们可能只需要逐行读取CSV文件中的数据,而不是一次性读取整个文件,这时,我们可以使用pandas库中的read_csv()函数的chunksize参数来实现。chunksize参数允许我们指定每次读取的行数,如果我们想要每次读取5行数据,可以使用以下代码:
chunksize = 5
for chunk in pd.read_csv('data.csv', chunksize=chunksize):
print(chunk)
这段代码将逐行读取CSV文件中的数据,并将每5行数据存储在一个名为chunk的DataFrame对象中,我们可以对这些数据进行处理或分析。
4. 关闭已打开的文件
当我们完成对CSV文件的操作后,应该关闭已打开的文件以释放资源,在pandas中,我们可以使用close()方法来关闭文件。
chunk.close()
需要注意的是,这里的close()方法是针对每个chunk对象调用的,在上面的例子中,我们在循环内部处理了每个chunk对象,因此需要在循环结束后调用它们的close()方法,如果你直接处理整个CSV文件(即不使用chunksize参数),则不需要调用close()方法,因为pandas会自动处理文件的关闭。
归纳一下,本教程介绍了如何使用pandas逐行读取CSV文件,我们首先导入了pandas库,然后使用read_csv()函数读取CSV文件,接着,我们使用chunksize参数实现了逐行读取数据的功能,我们关闭了已打开的文件以释放资源,希望这些内容对你有所帮助!
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/286176.html
相关文章
-
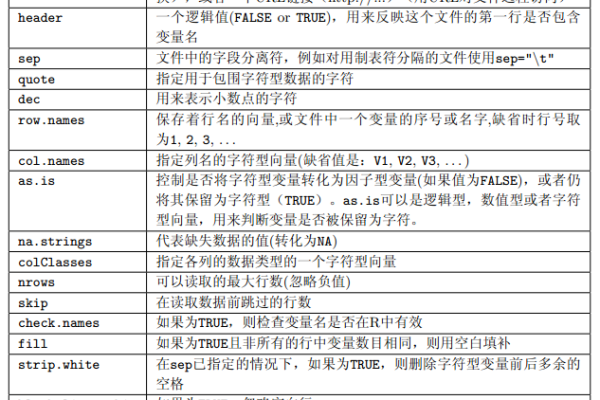
如何实现RecordReader按行读取「fread按行读取」
-

如何将pandas读取csv的路径设置为默认
-

剪映文字怎么逐行出现-剪映文字逐行出现的方法
-
如何导出MySQL数据为CSV文件并读取CSV文件?
-
pandas 逐行遍历
-
FastPanel面板怎么样?FastPanel是一款简单易用且功能强大的免费服务器管理面板,它具有用户友好、现代设计的可视化界面,操作便捷。FastPanel面板和国外主流的cPanel面板、Ple
-
如何使用Data Lake Analytics + OSS分析CSV格式的TPC-H数据集「csv数据分析软件」
-
函数搜索教程,pandas库安装(pandas函数库手册)








