java程序频繁查询数据库信息

频繁查询数据库信息可能会导致性能下降,建议使用缓存技术或者优化SQL语句来提高查询效率。
问题描述
在Java程序中,频繁查询数据库可能会导致以下问题:
1、响应时间变慢:每次查询都需要与数据库建立连接、发送请求、等待响应,这个过程会消耗一定的时间,当查询次数较多时,总的响应时间会明显增加。
2、数据库压力增大:频繁的查询会给数据库带来较大的负载,可能导致数据库性能下降,甚至崩溃。
3、网络带宽占用:每次查询都需要通过网络传输数据,频繁查询会增加网络带宽的占用,影响其他应用的正常运行。
解决方案
为了解决Java程序频繁查询数据库的问题,可以采取以下措施:

1、使用缓存:将查询结果缓存起来,下次查询时直接从缓存中获取,减少对数据库的访问次数。
2、优化SQL语句:编写高效的SQL语句,减少查询的数据量和计算量。
3、批量查询:将多个查询合并成一个查询,减少查询次数。
4、延迟加载:非关键数据可以采用延迟加载的方式,只有当用户需要时才去查询数据库。

5、使用连接池:合理配置数据库连接池,复用数据库连接,减少连接建立和关闭的开销。
具体实现
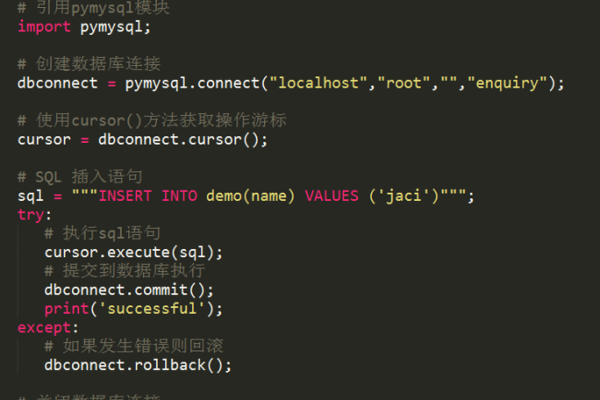
以使用缓存为例,可以使用Spring框架的@Cacheable注解来实现缓存功能,以下是一个简单的示例:
1、引入依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>springbootstartercache</artifactId>
</dependency>
2、启用缓存:

在Spring Boot的主类上添加@EnableCaching注解,开启缓存功能。
3、编写Service类:
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Cacheable(value = "users", key = "#id")
public User getUserById(Long id) {
// 模拟从数据库中查询用户信息
return new User(id, "张三");
}
}
在这个示例中,我们使用了@Cacheable注解来标记getUserById方法,当调用这个方法时,Spring会先检查缓存中是否存在对应的数据(key为方法参数id),如果存在,则直接返回缓存中的数据;如果不存在,则执行方法体中的代码(模拟从数据库中查询用户信息),并将结果存入缓存,这样,下次调用这个方法时,就可以直接从缓存中获取数据,减少了对数据库的访问次数。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11