上一篇
正则表达式基本语法详解
正则表达式是一种强大的文本处理工具,用于匹配、查找和替换字符串。本教程将详细介绍 正则表达式的基本语法,包括 字符类、量词、分组、选择、锚点等常用元素。
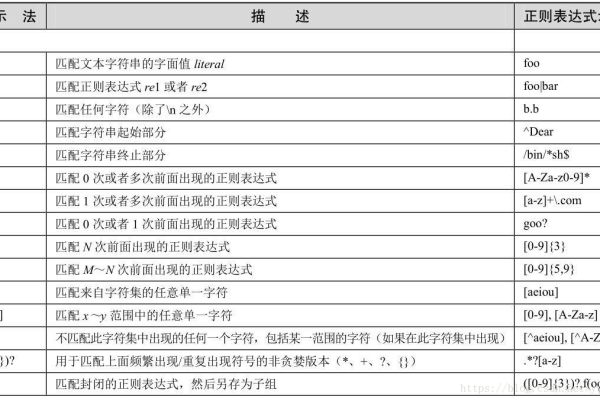
正则表达式,也称为regex、regexp或RE,是一种用于匹配字符串的强大工具,它可以用来检查一个字符串是否包含某个子串、将匹配的子串替换为其他字符串、选取符合某些条件的子串等,正则表达式的基本语法包括以下几个部分:

1、字符类
字符类用于匹配单个字符,例如[abc]可以匹配字符a、b或c,常用的字符类有以下几种:
[]:表示字符集合,例如[abc]表示a、b或c。
-:表示范围,例如[a-z]表示a到z之间的任意一个字符。
^:表示非,例如[^abc]表示除了a、b、c之外的任意一个字符。
:表示转义,例如d表示数字0到9。
2、量词
量词用于指定匹配次数,例如*表示匹配0次或多次,+表示匹配1次或多次,?表示匹配0次或1次,常用的量词有以下几种:
*:表示匹配0次或多次。
+:表示匹配1次或多次。
?:表示匹配0次或1次。
{m,n}:表示匹配m到n次。
{m,}:表示匹配m到无限次。
{n,}:表示匹配n到无限次。
3、边界符
边界符用于指定匹配的位置,例如^表示字符串的开头,$表示字符串的结尾,b表示单词的边界,常用的边界符有以下几种:
^:表示字符串的开头。
$:表示字符串的结尾。
b:表示单词的边界。
B:表示非单词的边界。
:表示行首。
:表示行尾。
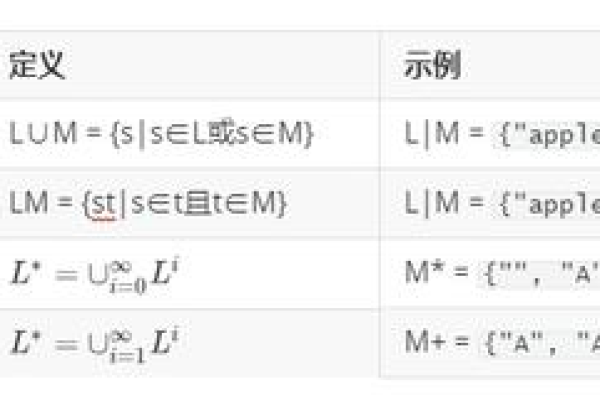
4、分组与捕获
分组与捕获用于将多个字符组合成一个整体,以便进行更复杂的匹配和替换操作,常用的分组与捕获有以下几种:
():表示分组,例如(ab)*表示匹配0个或多个ab。
|:表示或,例如a|b表示匹配a或b。
()?:表示非捕获分组,例如(ab)*?表示尽可能少地匹配ab。
(?:):表示非捕获分组,例如(?:ab)+表示匹配1个或多个ab,但不捕获它们。
5、预定义字符类
预定义字符类是一些特殊的字符类,可以直接使用,无需在前面加上反斜杠,常用的预定义字符类有以下几种:
d:表示数字0到9。
D:表示非数字。
w:表示字母、数字或下划线。
W:表示非字母、非数字和非下划线。
s:表示空白字符,如空格、制表符、换行符等。
S:表示非空白字符。
6、转义序列
转义序列用于匹配特殊字符,例如.表示匹配点号(.),而不是任意字符,常用的转义序列有以下几种:
.:表示点号(.)。
t:表示制表符(t)。
\rfvaeuXXXX:分别表示回车符(r)、换页符(f)、垂直制表符(v)、响铃符(a)、回退符(e)和Unicode字符(uXXXX)。
7、贪婪与懒惰模式
贪婪与懒惰模式用于控制量词的行为,例如默认情况下,量词是贪婪的,即尽可能多地匹配字符;但可以通过在量词后面加上问号(?),使其变为懒惰的,即尽可能少地匹配字符。*?表示懒惰的0次或多次匹配,而不仅仅是贪婪的0次或多次匹配。
8、零宽断言
零宽断言用于在不消耗字符的情况下,对目标位置进行判断,常用的零宽断言有以下几种:
`===…==========<本篇回答已经详细介绍了正则表达式的基本语法,包括字符类、量词、边界符、分组与捕获、预定义字符类、转义序列、贪婪与懒惰模式以及零宽断言等内容,接下来,我将回答四个与本文相关的问题,并给出解答。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/284502.html