DELL戴尔怎么更新系统

戴尔电脑更新系统通常通过Windows Update进行。用户需打开设置,进入更新与安全,检查更新,下载安装最新补丁和驱动。也可使用戴尔官方网站的支持页面获取驱动程序更新。
更新DELL戴尔电脑系统是一个相对简单的过程,但为了确保顺利和安全,遵循正确的步骤至关重要,以下是详细的技术介绍,帮助你完成戴尔电脑系统的更新。
准备工作
在开始更新之前,请确保备份所有重要文件,以防在更新过程中发生意外导致数据丢失,你可以使用戴尔自带的备份软件,或者手动将文件复制到外部硬盘或云存储中。
检查系统更新
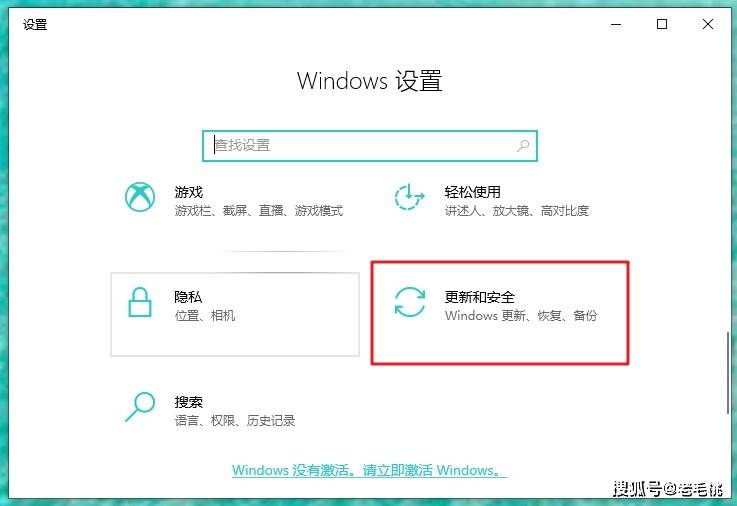
1、打开“设置”菜单,选择“更新与安全”。
2、点击“Windows Update”,系统将自动检查可用的更新。
3、如果有可用的更新,点击“下载”并等待下载完成。
安装更新
1、下载完成后,重启你的戴尔电脑。
2、在启动过程中,Windows可能会要求你进行进一步的安装步骤。
3、按照屏幕上的指示操作,直到更新完全安装完毕。
驱动程序更新
除了系统更新之外,确保所有的硬件驱动程序都是最新的也很重要。

1、访问戴尔官方网站,输入你的电脑型号,查找对应的驱动程序页面。
2、根据提示下载并安装最新的驱动程序。
可选更新
对于希望优化性能或添加新功能的用户,可以考虑以下可选更新:
1、访问Windows应用商店,搜索并安装第三方清理工具或系统优化软件。
2、考虑安装额外的安全软件,如防干扰程序或防火墙。
监控更新进度
在更新过程中,保持耐心并监控进度条,大型更新可能需要较长时间来完成安装,不要在此时关闭电脑。
处理更新问题
如果遇到任何更新问题,比如卡住不动或出现错误代码,可以尝试以下方法解决:

1、重新启动电脑,再次尝试更新过程。
2、访问戴尔支持论坛或联系客服获取帮助。
后续维护
更新完成后,定期检查新的系统更新和驱动更新,以保持电脑的最佳性能。
相关问题与解答
Q1: 如果Windows Update无法找到任何更新,我该怎么办?
A1: 确保你的网络连接正常,并且运行了最新的Windows版本,如果问题仍然存在,可以访问微软的支持页面寻求帮助。
Q2: 更新失败并显示错误代码,我该如何解决?

A2: 记录下错误代码并在微软支持页面搜索相关解决方案,如果问题复杂,建议联系戴尔技术支持。
Q3: 我应该在何时进行系统更新?
A3: 推荐在电脑闲置且连接到稳定电源时进行系统更新,以避免中断。
Q4: 如何手动启动系统更新检查?
A4: 在“设置”>“更新与安全”>“Windows Update”中,点击“检查更新”按钮即可手动启动检查。
保持系统和驱动程序的最新状态是确保戴尔电脑稳定性和安全性的关键步骤,通过上述步骤,你可以轻松地为你的戴尔电脑安装最新更新,享受更好的计算体验。
相关文章
-
该如何取消win10自动更新系统呢「该如何取消win10自动更新系统呢苹果」
-

xshell官网地址,Xshell登录2022年更新(xshell 官网)「xshell官方网站」
-
戴尔怎么进入bios
-
Arch Linux中怎么更新系统和软件包
-
OpenBSD中怎么更新系统和软件包
-

xshell如何连接交换机(xshell怎么连接)(xshell怎样连接交换机)
-
Dell服务器重装系统完全指南,让您轻松搞定系统重装! (dell服务器重装系统)
-
Dell服务器系统装机攻略: 简明易懂的安装步骤! (dell服务器怎么装系统)
-

微信怎么设置个性主题,微信怎么更换主题_微信怎么设置个性主题,微信怎么更换主题壁纸








