上一篇
数据仓库与ETL,它们在数据管理中扮演着怎样不同的角色?
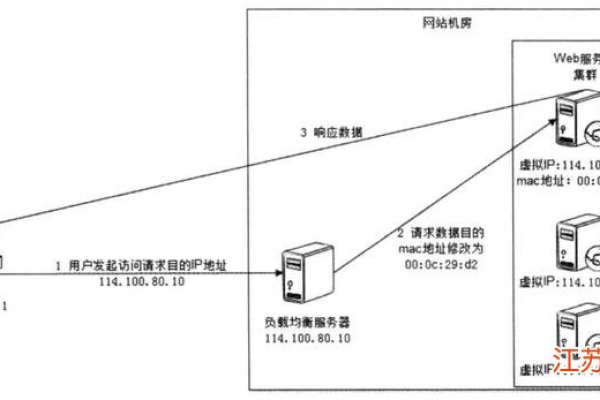
数据仓库是用于存储和管理来自不同来源的数据的集中式系统,而ETL(提取、转换、加载)是用于将数据从源系统移动到 数据仓库的过程。简而言之,数据仓库是目的地,ETL是到达那里的过程。
数据仓库和ETL是数据集成和管理领域中的两个核心概念,它们在企业信息化和数据分析中扮演着至关重要的角色,数据仓库用于存储大量的业务数据,便于进行高效的查询和分析,而ETL(Extract, Transform, Load)则是将数据从源端转换并加载到数据仓库中的一系列过程,它们在功能定义、数据处理流程以及技术工具等方面有所区别,具体分析如下:
1、功能定义
ETL:其主要作用是作为一个数据管道,将数据从多个源系统提取出来,经过必要的转换处理后,加载到一个目标系统中,通常是数据仓库。
数据仓库:它是一个中央数据库,专门为查询和分析而设计,能够存储大量来自不同源的数据,并将这些数据组织起来以便于快速访问和分析。
2、数据处理流程
ETL:包含三个步骤,抽取(Extract)、转换(Transform)、和加载(Load),数据被从原始数据源抽取出来;数据经过一系列的清洗、转换操作;处理过的数据被加载到目标系统中。
数据仓库:它接收经过ETL处理的数据,通过使用特定的数据模型如星型模式或雪花模式来优化查询性能,从而使得终端用户能够高效进行数据查询和报告生成。
3、技术工具
ETL:涉及各种工具和技术,如Informatica PowerCenter、Microsoft SQL Server Integration Services (SSIS)、和Apache NiFi等,这些工具帮助数据工程师自动化ETL过程。
数据仓库:常见的技术实现包括Amazon Redshift、Google BigQuery、Snowflake Computing、以及传统的Teradata等,这些技术提供了大规模数据存储和高速查询处理能力。
4、应用场景
ETL:通常用于数据集成、数据迁移和数据同步的场景,例如在需要将来自多个部门或系统的数据统计到一个统一平台进行分析时。
数据仓库:主要用于商业智能(BI)和数据分析的后端存储,支持复杂的SQL查询、报告生成和数据挖掘任务。
5、数据质量
ETL:确保数据在转换过程中的质量,通过数据清洗和一致性检查来提升数据的可用性和准确性。
数据仓库:依赖于ETL提供的数据质量,但更关注于数据的组织和存储效率,以确保高性能的数据检索。
6、性能考量
ETL:重点是优化数据处理过程,减少处理时间和资源消耗,特别是在处理大数据量时需要考虑性能。
数据仓库:焦点在于优化数据存储结构和查询性能,通常通过索引优化、查询缓存和并行处理技术来提升性能。
7、维护成本
ETL:可能涉及较高的初始设定成本,因为需要设计和测试数据转换逻辑,但长期看有助于减少数据冗余和维护成本。
数据仓库:初期建立成本较高,但随着时间的推移,它能显著降低数据分析和报告的复杂性,从而减少整体的业务运营成本。
针对上述分析,提出以下几点建议:
选择合适的ETL工具对成功实施数据集成项目至关重要,应根据数据类型、体积、及企业的特定需求来决定。
随着数据的增长,数据仓库的可扩展性成为重要考虑因素,应选择能够适应未来数据增长的存储解决方案。
ETL和数据仓库虽然在功能上有所不同,但它们互为补充,ETL负责将数据从源系统有效地转移到数据仓库,而数据仓库则提供了一个优化的平台来存储和分析这些数据,理解它们之间的区别和联系对于构建有效的数据架构至关重要,在设计企业级的数据解决方案时,合理的ETL流程和强大的数据仓库功能是实现数据驱动决策的关键。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/278670.html