如何使用JavaScript包含一个类?

JavaScript 中的 “class” 是一个用于创建对象的模板。它定义了对象的属性和方法,这些属性和方法可以在创建新对象时被继承。使用 “class” 关键字声明类,后跟类名、一对大括号以及 类的主体。在类主体中,可以使用各种 JavaScript 语法来定义对象的属性和方法。
JavaScript中的类(Class)
JavaScript ES6引入了类(Class)的概念,使得我们可以更简洁地创建对象和处理继承,下面详细介绍JavaScript中类的源码实现。
1. 类的定义
在JavaScript中,类是通过class关键字定义的,类可以包含构造函数、方法和其他属性。
class MyClass {
constructor(param1, param2) {
this.property1 = param1;
this.property2 = param2;
}
method1() {
// ...
}
static staticMethod() {
// ...
}
} 2. 类的实例化
要创建一个类的实例,可以使用new关键字。

const myInstance = new MyClass('value1', 'value2'); 3. 继承
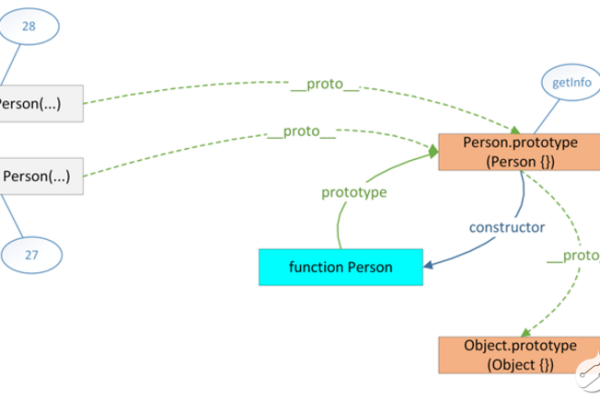
JavaScript中的类支持单继承,通过使用extends关键字来实现,子类可以通过super关键字调用父类的构造函数和方法。
class ParentClass {
constructor() {
// ...
}
parentMethod() {
// ...
}
}
class ChildClass extends ParentClass {
constructor() {
super(); // 调用父类的构造函数
// ...
}
childMethod() {
// ...
}
} 4. 访问器和设置器
类的属性可以通过getter和setter方法进行访问和修改。

class MyClass {
constructor() {
this._property = null;
}
get property() {
return this._property;
}
set property(value) {
this._property = value;
}
} 5. 静态属性和方法
类也可以有静态属性和方法,它们属于类本身而不是类的实例,静态方法和属性可以通过类名直接访问。
class MyClass {
static staticProperty = 'static value';
static staticMethod() {
console.log('This is a static method.');
}
}
console.log(MyClass.staticProperty); // 输出 "static value"
MyClass.staticMethod(); // 输出 "This is a static method." 相关问题与解答:
问题1:如何在JavaScript中使用类?

解答:在JavaScript中,你可以使用class关键字来定义一个类,类可以包含构造函数、方法和属性,要创建一个类的实例,可以使用new关键字。
class MyClass {
constructor(name) {
this.name = name;
}
greet() {
console.log(Hello, ${this.name}!);
}
}
const myInstance = new MyClass('Alice');
myInstance.greet(); // 输出 "Hello, Alice!" 问题2:如何在JavaScript中实现继承?
解答:在JavaScript中,你可以通过使用extends关键字来实现类的继承,子类可以通过super关键字调用父类的构造函数和方法。
class Animal {
constructor(name) {
this.name = name;
}
speak() {
console.log(${this.name} makes a noise.);
}
}
class Dog extends Animal {
speak() {
console.log(${this.name} barks.);
}
}
const dog = new Dog('Rex');
dog.speak(); // 输出 "Rex barks." 






热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11