MapReduce Java API接口,如何深入理解其核心功能与应用实例?

MapReduce Java API 接口介绍
MapReduce 是一种编程模型,用于大规模数据集(大于1TB)的并行运算,Hadoop 是一个开源的框架,实现了 MapReduce 编程模型,使得用户能够轻松地将程序分布到大量廉价的计算机上执行,Java API 是 Hadoop 提供的用于开发 MapReduce 程序的接口。
基本概念
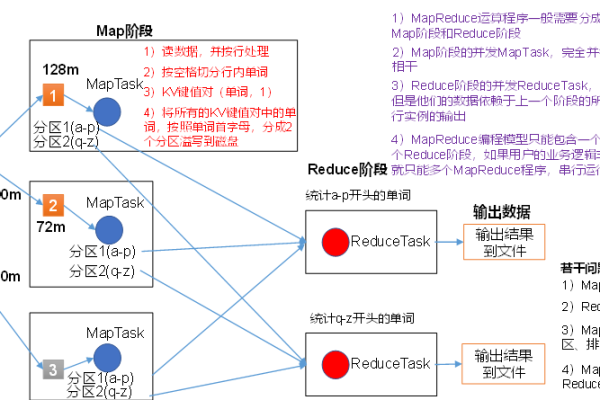
Mapper: 处理输入数据,输出键值对。
Reducer: 处理来自 Mapper 的输出,合并键值对。
Combiner: 可选组件,用于减少网络传输的数据量。
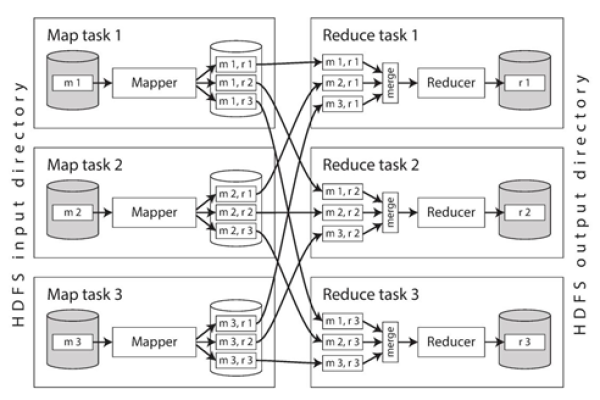
Shuffle and Sort: 在 Mapper 和 Reducer 之间进行数据排序和分发。
主要接口
1. Mapper 接口
public interface Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
{
void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException;
}
KEYIN:输入键的类型。
VALUEIN:输入值的类型。
KEYOUT:输出键的类型。

VALUEOUT:输出值的类型。
Context:当前任务的上下文信息,用于输出键值对。
2. Reducer 接口
public interface Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
{
void reduce(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException;
}
KEYIN:输入键的类型。
VALUEIN:输入值的类型。
KEYOUT:输出键的类型。
VALUEOUT:输出值的类型。

Context:当前任务的上下文信息,用于输出键值对。
3. Combiner 接口
public interface Combiner<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
{
void combine(KEYIN key, Iterable<VALUEIN> values, Context context) throws IOException, InterruptedException;
}
与 Reducer 类似,但仅在同一个 Mapper 任务内部执行。
4. Context 接口
public interface Context
{
void write(KEYOUT key, VALUEOUT value) throws IOException;
// 其他方法,如获取作业信息等。
}
用于在 Mapper 和 Reducer 中输出键值对。
5. Job 接口
public interface Job
{
void setJarByClass(Class<?> cls);
void setMapperClass(Class<? extends Mapper> mapperClass);
void setCombinerClass(Class<? extends Reducer> reducerClass);
void setReducerClass(Class<? extends Reducer> reducerClass);
// 其他配置方法,如设置输入输出路径等。
}
用于配置和提交 MapReduce 作业。

工作流程
1、编写 Mapper 和 Reducer 类。
2、创建一个 Job 实例,配置作业参数。
3、设置输入输出路径、Mapper 和 Reducer 类等。
4、提交作业到 Hadoop 集群执行。
5、获取作业执行结果。
MapReduce Java API 提供了一套完整的接口,用于开发分布式计算程序,通过使用这些接口,开发者可以轻松地将程序部署到 Hadoop 集群,实现大规模数据的并行处理。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20