DEDECMS 如何支持副栏目在独立模型中的修改?

在DEDECMS(织梦内容管理系统)中,独立模型是一种灵活的内容管理方式,它允许用户创建自定义的数据表和字段,以满足特定的业务需求,在实际使用过程中,我们经常会遇到需要对独立模型进行修改的情况,特别是对于一些复杂的网站结构,如副栏目的设置,本文将详细介绍如何在DEDECMS中支持副栏目修改,并提供相关的FAQs解答。
一、DEDECMS独立模型概述
DEDECMS独立模型是一种基于PHP和MySQL的内容管理系统,它提供了丰富的功能模块,包括文章发布、分类管理、标签管理等,独立模型是DEDECMS的一大特色,它可以让用户根据实际需求创建自定义的数据表和字段,从而实现对数据的灵活管理。
二、副栏目的概念及作用
副栏目是指在主栏目下再细分出的子栏目,通常用于展示更具体的内容分类,在一个新闻网站上,主栏目可能是“国内新闻”、“国际新闻”等,而副栏目则可能是“政治”、“经济”、“文化”等,通过设置副栏目,可以更好地组织和管理网站内容,提高用户体验。
三、DEDECMS独立模型支持副栏目修改的方法
1. 进入后台管理界面
登录到DEDECMS的后台管理界面,在浏览器地址栏输入http://你的域名/dede/index.php,然后输入管理员账号和密码进行登录。

2. 找到独立模型设置

在后台管理界面中,点击左侧菜单栏中的“模块”>“模型管理”>“独立模型”,你可以看到已经创建的所有独立模型。
3. 编辑独立模型
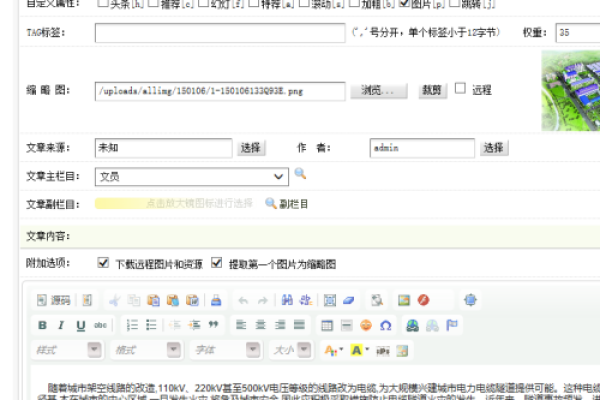
找到需要修改的独立模型,点击右侧的“编辑”按钮,在弹出的编辑窗口中,你可以对独立模型的各种属性进行修改,包括名称、描述、字段等。
4. 添加或修改副栏目字段
在编辑窗口中,找到“字段管理”选项卡,你可以添加新的字段或者修改现有的字段,为了支持副栏目修改,我们需要添加一个新的字段来存储副栏目的信息,点击“添加字段”按钮,填写相关信息,如字段名、类型、长度等,在“字段选项”中勾选“是否为主键”,并设置为“是”,这样,我们就为独立模型添加了一个副栏目字段。

5. 保存修改并更新缓存
完成以上操作后,点击“保存”按钮保存修改,回到后台管理界面,点击右上角的“生成”>“一键更新网站”>“更新所有”,这样可以确保我们的修改被正确地应用到网站上。
四、相关问答FAQs
Q1: DEDECMS独立模型支持副栏目修改吗?
A1: 是的,DEDECMS独立模型可以通过添加或修改字段来实现对副栏目的支持,具体操作方法如上所述。
Q2: 如何在DEDECMS中为独立模型添加副栏目字段?
A2: 在DEDECMS中为独立模型添加副栏目字段的方法如下:首先登录到后台管理界面,然后找到需要修改的独立模型并进行编辑;接着在“字段管理”选项卡中点击“添加字段”按钮,填写相关信息并勾选“是否为主键”;最后保存修改并更新缓存即可。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11