上一篇
hadoop核心组件
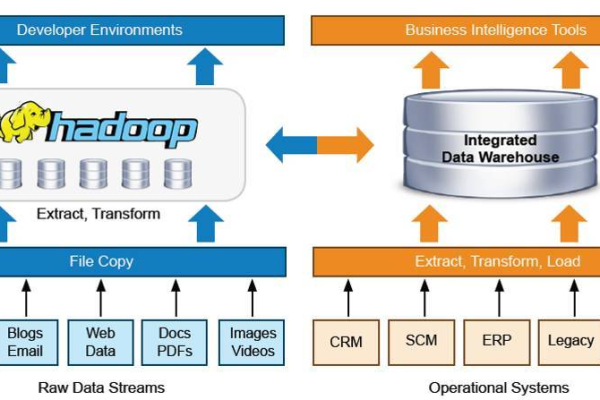
Hadoop的核心组件包括:HDFS(分布式文件系统,用于存储数据)、MapReduce(处理大数据集的编程模型)、YARN(作业调度和集群资源管理的框架),以及Common(库和实用工具,支持其他Hadoop模块)。
Hadoop是一个开源的分布式计算框架,用于处理大规模数据集,它的核心组件构成了其强大的数据处理能力的基础,包括HDFS、MapReduce和YARN,这些组件各自承担着数据存储、处理和管理的重要职能,共同支持了Hadoop的高效运行,以下是关于hadoop核心组件的相关介绍:

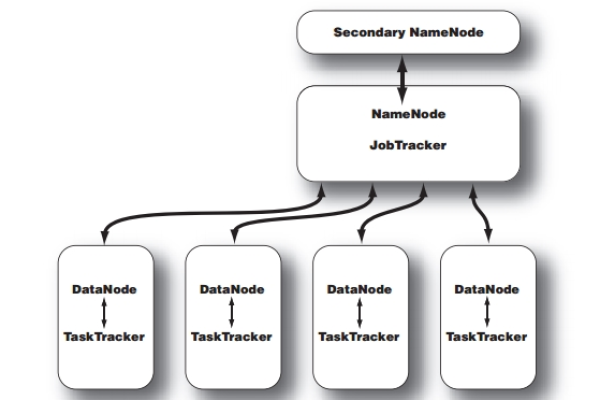
1、Hadoop分布式文件系统(HDFS):HDFS是Hadoop的分布式文件系统,设计用来在廉价的商用硬件上存储海量数据,它具有高容错性,能够自动保存数据的多个副本,确保数据的安全性和可靠性,HDFS采用主/从架构,其中NameNode作为主节点管理文件系统的元数据,而DataNode作为从节点存储实际数据。
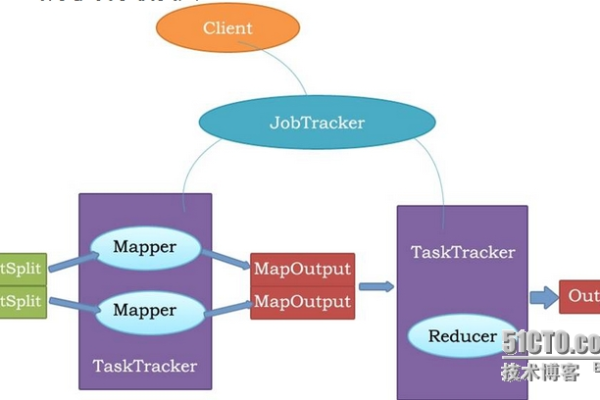
2、MapReduce:MapReduce是一个编程模型和一个用于大数据处理的执行框架,它用于编写应用程序,以在Hadoop集群上并行处理大数据集,MapReduce的工作分为两个阶段:Map阶段和Reduce阶段,Map函数处理输入数据的一部分,并生成键值对;Reduce函数则处理所有具有相同键的中间结果,以产生最终输出。
3、Yet Another Resource Negotiator(YARN):YARN是一个资源管理平台,负责在Hadoop集群中管理和调度计算资源,它将资源管理与计算分离,使得各种应用程序可以运行在Hadoop之上,不仅限于MapReduce任务,YARN主要由ResourceManager和NodeManager组成,ResourceManager负责全局的资源调度,而NodeManager则在每个节点上执行具体的任务。
Hadoop的核心组件HDFS、MapReduce和YARN共同构成了其强大的数据处理能力,它们分别负责数据的存储、处理和资源管理,确保了Hadoop能够在大规模数据集上进行高效的计算,随着技术的发展,Hadoop生态系统不断扩展,包括了更多的工具和服务,以支持更广泛的数据分析和处理需求。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/253329.html