负载均衡读写分离,如何实现高效的数据库性能优化?

负载均衡读写分离
背景与介绍
随着互联网的快速发展和数据量的急剧增加,数据库作为企业级应用的核心组成部分,其性能和稳定性对整个系统的运行具有至关重要的影响,为了有效提高数据库的性能和稳定性,数据库负载均衡与读写分离技术应运而生,本文将重点介绍这两种技术的基本概念、实现方法以及应用场景,并通过案例分析探讨其实际效果与优势。
基本概念
读写分离
读写分离是一种通过将数据库的读操作和写操作分配到不同的服务器上,以减少主数据库压力并提高系统整体性能的技术,在传统的数据库系统中,读操作和写操作往往会被绑定在一起,这会限制数据库系统的并发性能,通过读写分离技术,我们可以将读操作和写操作分开处理,将它们发送到不同的数据库服务器上,这样,多个数据库服务器可以同时处理读操作和写操作,从而提高系统的并发性能。
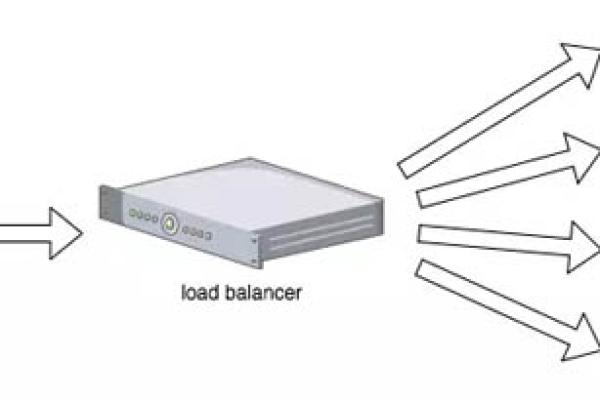
负载均衡
数据库负载均衡主要是通过在多个数据库服务器之间分配和平衡数据读写请求,以实现提高数据库整体性能的目的,传统的数据库负载均衡方案主要包括:轮询、随机、哈希等算法,这些算法能够在一定程度上实现负载均衡,但并不能很好地满足大规模数据应用场景下的负载均衡需求,为了更好地解决这一问题,分布式数据库架构开始受到广泛关注。
实现方法

读写分离的实现方法
程序实现:由开发人员在程序中实现读写分离,适用于自主开发的系统,优点是灵活,缺点是增加了开发人员的工作量和维护成本。
中间件实现:使用数据库中间件(如MyBatis、Hibernate等)来实现读写分离,优点是透明化,缺点是可能引入额外的性能损耗和复杂性。
负载均衡的实现方法
传统算法:轮询、随机、哈希等算法,适用于简单的负载均衡需求。
分布式数据库架构:将数据分散到多个节点上,采用分片技术进行水平或垂直拆分,优点是能够大大提高数据库系统的性能,缺点是实现复杂,需要解决数据分片、节点通信、数据同步等问题。
应用场景与案例分析

以一个在线购物平台为例,来分析数据库负载均衡与读写分离技术的应用效果与优势,该购物平台拥有大量的商品信息和用户数据,在高峰期时,大量的用户同时访问和购买商品,会对数据库系统造成巨大的压力,为了提高数据库的性能和稳定性,该平台采用了以下策略:
分布式数据库架构:将数据分散到多个节点上,并使用分片技术将数据进行水平拆分,这样,每个节点可以独立地处理一部分数据读写请求,从而大大提高了数据库系统的性能。
读写分离:结合负载均衡技术,将读操作和写操作分别发送到不同的数据库服务器上,通过这种方式,多个数据库服务器可以同时处理读操作和写操作,进一步提高了系统的并发性能。
自动故障切换机制:当某个数据库服务器出现故障时,系统会自动将读操作和写操作重定向到其他正常的数据库服务器上,以保证整个系统的可用性和稳定性。
未来展望

随着技术的不断发展,我们相信数据库负载均衡与读写分离技术将会在更多领域得到广泛应用和研究,未来的研究方向可以包括:优化数据分片算法、提高节点通信效率、进一步完善自动故障切换机制等。
数据库负载均衡与读写分离技术是提高数据库性能和稳定性的重要手段,在应用这两种技术时,我们需要根据实际业务需求和使用场景来选择合适的方案和产品,并合理配置相关参数,通过这种方式,我们可以更好地满足大规模数据应用场景下的高性能、高可用性需求。
各位小伙伴们,我刚刚为大家分享了有关“负载均衡读写分离”的知识,希望对你们有所帮助。如果您还有其他相关问题需要解决,欢迎随时提出哦!



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11