上一篇
Redis的时间序列数据库功能怎么实现
Redis通过Sorted Set和Hash数据结构实现时间序列数据库功能,支持存储、查询和删除指定时间范围内的数据。
Redis的时间序列数据库功能可以通过以下步骤实现:

1、数据结构选择:
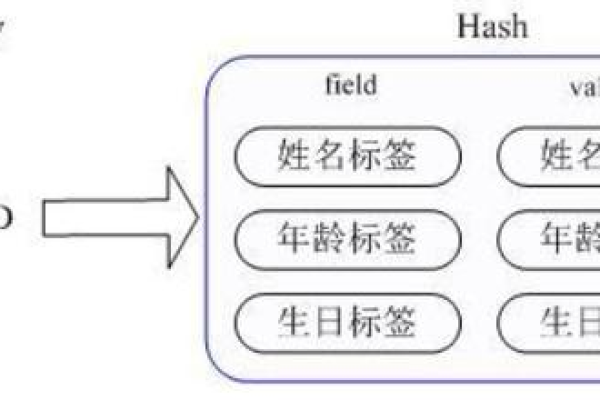
使用散列(Hash)数据结构存储每个时间序列的键值对。
时间戳作为散列的键,数据内容作为散列的值。
2、插入数据:
将时间戳作为键,将需要存储的数据作为值,插入到散列中。
如果该时间戳已经存在于散列中,则更新对应的值。
3、获取数据:
根据指定的时间戳,从散列中获取对应的值。
如果时间戳不存在于散列中,则返回空值或默认值。
4、删除数据:
根据指定的时间戳,从散列中删除对应的键值对。
5、数据过期处理:
可以使用Redis的过期设置来自动删除过期的时间序列数据。
可以为每个时间序列数据设置不同的过期时间。
6、数据压缩和优化:
可以使用Redis的压缩功能来减小内存占用。
可以定期对时间序列数据进行归档或备份,以减少数据的持久化成本。
相关问题与解答:
问题1:如何保证Redis的时间序列数据库的高性能?
答:为了保证Redis的时间序列数据库的高性能,可以考虑以下几个方面:
合理使用散列、有序集合等数据结构,根据实际需求选择合适的数据结构。
使用合适的过期策略,及时清理过期的数据,避免无用数据的占用。
针对写入操作,可以考虑使用管道批量写入,减少网络开销。
针对读取操作,可以使用缓存机制,减少对后端存储的访问频率。
针对大规模数据,可以考虑分片存储,将数据分散到多个Redis节点上。
问题2:如何处理Redis时间序列数据库中的高并发写入?
答:处理Redis时间序列数据库中的高并发写入可以考虑以下几个方面:
使用分布式锁来控制并发写入操作,确保同一时刻只有一个客户端能够写入数据。
使用异步写入方式,将写入操作放入队列中,由后台线程逐个处理,避免阻塞主线程。
针对热点数据,可以考虑使用读写分离的策略,将读操作和写操作分别路由到不同的Redis节点上,减轻单个节点的压力。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/247094.html