如何有效配置Hive中的MapReduce和MapJoin参数以优化性能?

hive.auto.convert.join、
hive.mapjoin.smalltable.filesize 和
hive.mapjoin.io.sort.factor。
Hive的MapReduce配置参数在处理大规模数据集时至关重要,这些参数能够显著影响查询性能和资源使用效率,特别是在进行表连接(join)操作时,以下是一些常用的MapReduce MapJoin Hive配置参数:

| 参数名称 | 说明 | 默认值 |
| hive.auto.convert.join | 如果为true,Hive会自动将符合条件的普通join转换为map join。 | true |
| hive.mapjoin.smalltable.filesize | 设置可以放入内存的小表的大小上限,超过此大小的表不会转为map join。 | 25000000字节 |
| hive.auto.convert.join.noconditionaltask | 如果为true,多个小表的map join会合并为一个任务执行,以减少I/O操作次数。 | true |
| hive.auto.convert.join.noconditionaltask.size | 设置多个map join合并后的小表文件大小总和的最大值。 | 30000000字节 |
| mapreduce.job.name | 设置作业名,方便定位具体任务。 | |
| mapreduce.input.fileinputformat.split.maxsize | 设置Map输入合并大小。 | 300000000字节 |
| mapreduce.input.fileinputformat.split.minsize | 设置Map输入合并最小大小。 | 100000000字节 |
| mapreduce.input.fileinputformat.split.minsize.per.node | 设置每个节点的Map输入合并最小大小。 | 100000000字节 |
| mapreduce.input.fileinputformat.split.minsize.per.rack | 设置每个机架的Map输入合并最小大小。 | 100000000字节 |
| hive.exec.reducers.bytes.per.reducer | 设置每个reduce任务处理的数据量。 | 300000000字节 |
| hive.exec.reducers.max | 设置最大reduce任务数。 | 300 |
| hive.merge.mapfiles | 是否在Maponly的任务结束时合并小文件。 | true |
| hive.merge.mapredfiles | 是否在MapReduce的任务结束时合并小文件。 | true |
| hive.merge.size.per.task | 合并文件的大小。 | 256*1024*1024字节 |
| hive.merge.smallfiles.avgsize | 当输出文件的平均大小小于该值时,启动一个独立的mapreduce任务进行文件merge。 | 16*1024*1024字节 |
| hive.auto.convert.join | 是否开启map join。 | false |
在使用Hive进行MapReduce操作时,合理设置这些参数可以显著提高查询性能和资源使用效率,通过调整hive.auto.convert.join和hive.mapjoin.smalltable.filesize等参数,可以控制何时以及如何将普通的表连接操作转换为更高效的Map Join操作,通过设置mapreduce.input.fileinputformat.split.maxsize和mapreduce.input.fileinputformat.split.minsize等参数,可以控制输入数据的分割方式,进而影响Map和Reduce任务的数量和执行效率。
理解和掌握这些常用配置参数对于优化Hive查询性能至关重要,通过合理设置这些参数,可以根据具体的数据和查询需求,调整Hive的行为,以达到最佳的性能表现。


| 配置参数 | 说明 | 默认值 |
| mapjoin.buckets | 设置MapJoin的bucket数量,用于将小表数据分布到多个bucket中,减少merge join时的shuffle量 | 10 |
| mapjoin.reduce.tasks | 设置MapJoin的reduce任务数量,控制MapJoin任务并行度 | 1 |
| mapjoin.key.max.size | 设置MapJoin中键的最大大小,超过此大小的键将被分配到reduce任务中处理 | 1GB |
| mapjoin.algo | 设置MapJoin的算法,包括:simple(简单算法),bucket(bucket mapjoin),block(block mapjoin) | simple |
| mapjoin.memory.min | 设置MapJoin任务的最小内存使用量,单位为MB | 100 |
| mapjoin.memory.max | 设置MapJoin任务的最大内存使用量,单位为MB | 100 |
这些配置参数有助于优化Hive中的MapJoin操作,提高查询性能,在实际应用中,您可以根据具体需求调整这些参数。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/24306.html
相关文章
-
如何配置MapReduce和MapJoin以优化Hive性能?
-

如何使用MapReduce实现JOIN操作?——深入探讨MapReduce Join实例
-
JavaScript在MapReduce框架中为何不兼容,导致mapreduce.js的javascript_MapReduce不支持?
-
kill mapreduce job_配置MapReduce Job基线
-
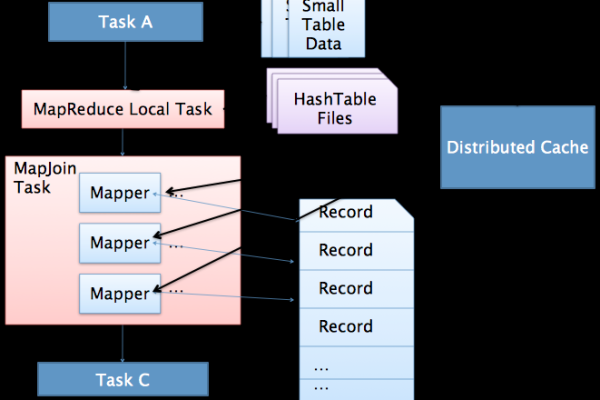
Hive中MapJoin操作的关键配置参数有哪些?
-
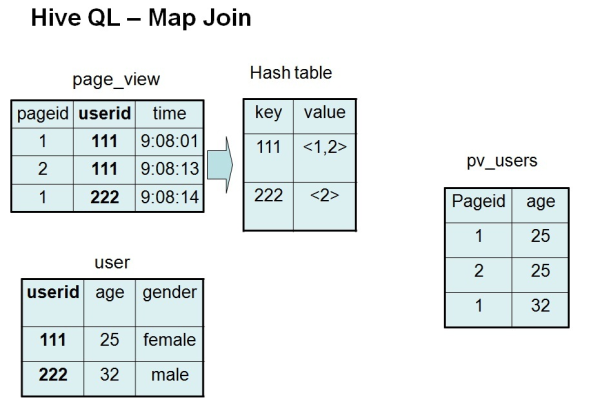
Hive中MapJoin的配置参数有哪些关键设置,对于提高数据处理效率有何影响?
-
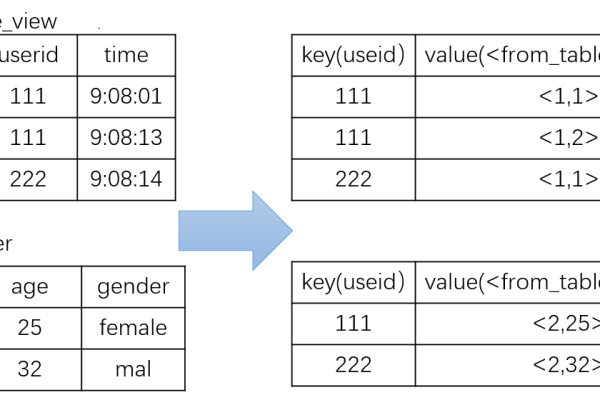
在Hive中如何实现MapReduce环境下两张表Join操作的效率提升与优化策略?
-
MapReduce和Writable,如何开发高效的MapReduce应用?