
上一篇
HBase如何处理数据的分布和负载均衡
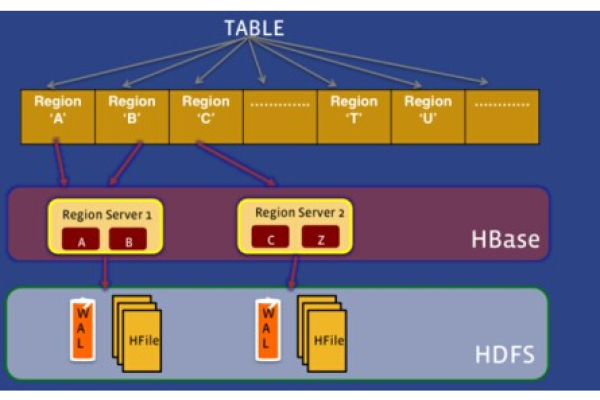
HBase通过Row Key设计,数据按照Row Key分布式存储在不同Region上。当某个Region负载过高时,HBase会自动触发Region Split操作,将数据重新分布到其他Region,实现负载均衡。
HBase是一个分布式、可扩展的大数据存储系统,它通过一系列机制来处理数据的分布和负载均衡,以下是HBase如何处理数据分布和负载均衡的详细说明:
1. 数据分布
HBase通过以下方式实现数据的分布:
1.1 行键(Row Key)设计
HBase中的数据按照行键进行排序和分布,合理的行键设计可以确保数据在各个Region Server上均匀分布,从而提高查询效率和避免热点问题。
1.2 Region划分
HBase表被划分为多个Region,每个Region包含一定范围的行键,Region的数量可以根据数据量和查询需求进行调整。
1.3 Region Server
每个Region Server负责管理一部分Region,数据在各个Region Server之间进行分布,当某个Region Server的负载过高时,可以通过调整Region的数量和分布来达到负载均衡。
2. 负载均衡
HBase通过以下方式实现负载均衡:
2.1 Region Split
当某个Region的大小超过阈值时,HBase会将其拆分为两个子Region,从而实现数据的重新分布和负载均衡。
2.2 Region Merge
当多个Region的大小过小且访问频率较低时,HBase会将它们合并为一个较大的Region,以减少管理开销。
2.3 动态Region分配
HBase会根据Region Server的负载情况,动态调整Region的分配,当某个Region Server的负载过高时,HBase会将其部分Region迁移到其他Region Server上,以实现负载均衡。
2.4 数据块缓存
HBase会对热点数据进行缓存,以提高查询效率,缓存策略也有助于实现负载均衡,因为缓存可以减少对底层存储系统的压力。
相关问题与解答
Q1: HBase如何保证数据的一致性?
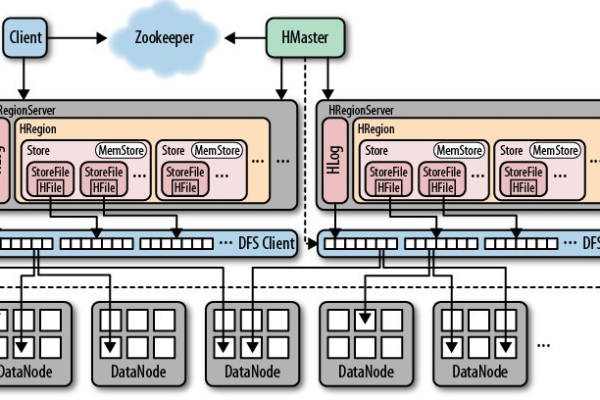
A1: HBase通过WAL(WriteAhead Logging)机制保证数据的一致性,当数据写入HBase时,首先将操作记录到WAL日志中,然后再写入内存,当发生故障时,可以通过WAL日志恢复数据。
Q2: HBase如何处理读写分离?
A2: HBase通过Pessimistic Concurrency Control(PCC)或Optimistic Concurrency Control(OCC)机制处理读写分离,PCC机制通过锁定行键来实现,而OCC机制则依赖于版本号和时间戳,这两种机制可以确保在高并发场景下,数据的读写操作不会相互干扰。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/241922.html
相关文章
-
HBase中怎么处理数据的分区和负载均衡
-

云服务器负载均衡,云计算负载均衡2022年更新(云服务器负载均衡,云计算负载均衡2022年更新吗)
-
Docker中Swarm服务发现和负载均衡原理分析(docker swarm服务发现与负载均衡原理分析)
-
Couchbase中怎么实现数据分片和负载均衡
-
腾讯云负载均衡(腾讯云负载均衡clb支持的策略)(腾讯云负载均衡使用教程)
-
云负载均衡器(云计算负载均衡)(云负载均衡的组件有哪些)
-
一文看懂集群、分布式与负载均衡的关系(集群分布式负载均衡区别)
-
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。