
上一篇
hadoop怎么解决存储和数据处理
Hadoop是一个开源的分布式计算框架,它能够处理大规模的数据集,Hadoop的核心组件包括HDFS(Hadoop Distributed File System)和MapReduce,HDFS负责存储数据,而MapReduce则负责处理数据,下面我们将详细讲解Hadoop如何解决存储和数据处理的问题。

Hadoop存储解决方案:HDFS
1、HDFS简介
HDFS是一个高度容错性的分布式文件系统,它可以在低成本的硬件上运行,并提供高吞吐量的数据访问,HDFS的设计目标是能够存储PB级别的数据,并能够处理大量的并发读写操作。
2、HDFS架构
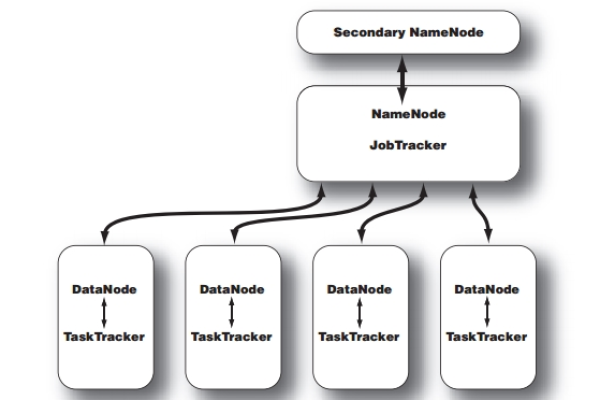
HDFS采用主从架构,主要包括NameNode和DataNode两种角色。
NameNode:负责管理文件系统的元数据,如文件名、文件块信息等,NameNode还负责客户端的请求调度,以及DataNode的管理。
DataNode:负责存储实际的数据,DataNode将数据分成多个数据块(block),并将这些数据块存储在本地磁盘上。
3、HDFS数据存储原理
当客户端向HDFS写入数据时,数据会被分成多个数据块,并存储在不同的DataNode上,每个数据块会有一个副本,这些副本会分布在不同的DataNode上,以保证数据的可靠性,当客户端读取数据时,它会从距离最近的DataNode上获取数据,以提高访问速度。
4、HDFS的容错机制
HDFS通过以下方式实现容错:
副本策略:每个数据块会有多个副本,分布在不同的DataNode上,当某个DataNode发生故障时,其他副本仍然可以保证数据的完整性。
心跳检测:NameNode会定期与DataNode进行通信,以检测DataNode的状态,当发现某个DataNode失效时,NameNode会将其上的副本迁移到其他正常的DataNode上。
数据校验:HDFS会对写入的数据进行校验,以确保数据的完整性。
Hadoop数据处理解决方案:MapReduce
1、MapReduce简介
MapReduce是一个分布式计算框架,它允许用户在大量计算机上并行处理数据,MapReduce的核心思想是将计算任务分解成两个阶段:Map阶段和Reduce阶段。
2、MapReduce工作原理
Map阶段:将输入数据分成多个数据块,并将这些数据块分发到不同的计算节点上进行处理,每个计算节点会对数据块进行映射(mapping)操作,生成一组键值对(keyvalue)。
Shuffle阶段:将Map阶段生成的键值对按照键进行排序和分组,以便将相同的键发送到同一个Reduce节点上进行处理。
Reduce阶段:对具有相同键的键值对进行归约(reducing)操作,生成最终的输出结果。
3、MapReduce容错机制
MapReduce通过以下方式实现容错:
任务监控:MapReduce会对正在执行的任务进行监控,当发现某个任务失败时,会自动重新执行该任务。
数据备份:MapReduce会为每个任务生成一个备份,当原始任务失败时,可以使用备份恢复任务。
任务重试:对于失败的任务,MapReduce会尝试重新执行一定次数,直到任务成功或达到最大重试次数。
Hadoop通过HDFS实现了大规模数据的存储,通过MapReduce实现了大规模数据的并行处理,这两个组件相互配合,使得Hadoop成为了一个强大的大数据处理平台。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/241236.html
相关文章
-
大数据处理hadoop_SQL on Hadoop
-
如何用1037u家用服务器轻松解决存储和数据备份的挑战?
-
如何利用MapReduce和Hadoop实现高效的SQL on Hadoop处理?
-
kafka 存储hadoop_SQL on Hadoop
-
Hadoop Jar包冲突影响Flink作业提交?如何解决MapReduce与Hadoop的兼容性问题?
-
MongoDB与Hadoop集成,SQL on Hadoop带来了哪些新机遇?
-
安装hadoop_SQL on Hadoop
-
服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。








