上一篇
什么是负载均衡芯片?它如何提升系统性能?
原理、应用与实现

总述
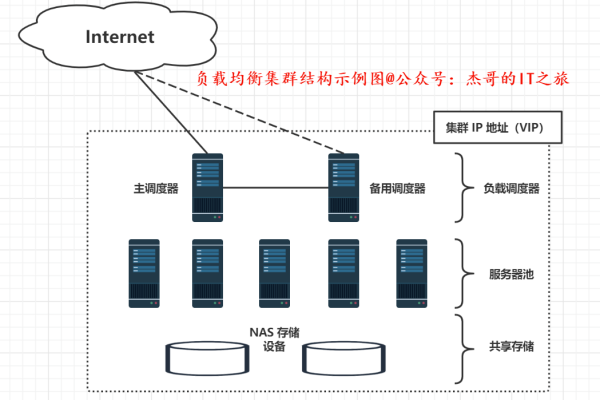
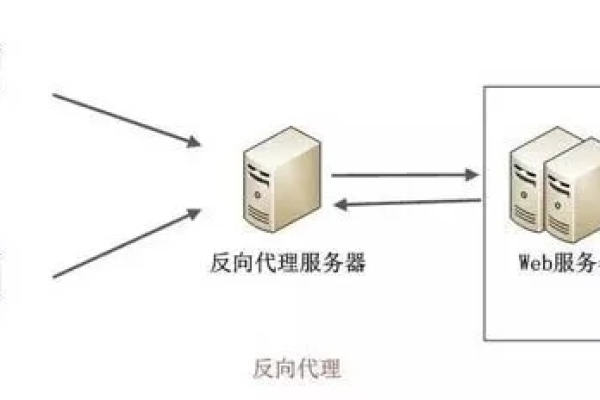
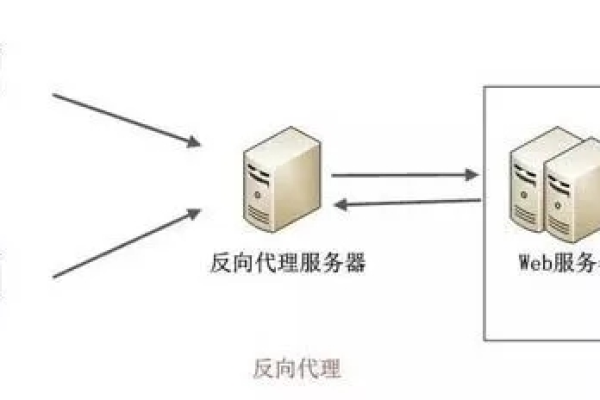
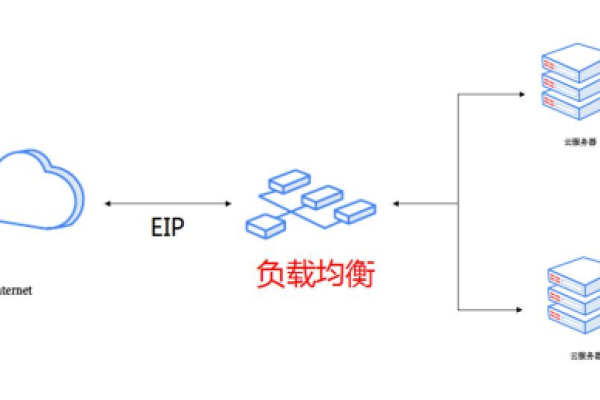
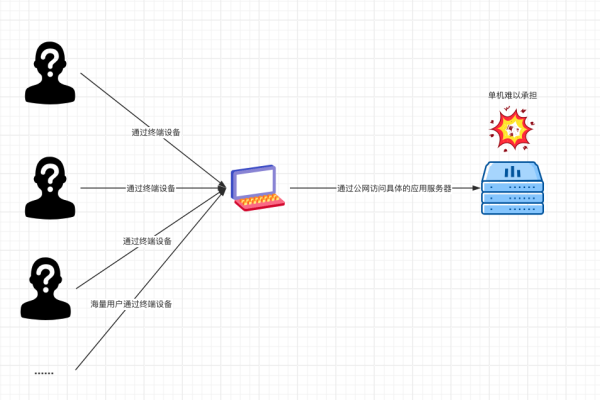
负载均衡芯片是一种专门设计用于在多处理器或多核系统中高效分配任务的硬件设备,其主要目的是确保所有处理单元均匀地分摊工作负载,以避免某些单元过载而其他单元闲置的情况,通过合理的任务调度和资源分配,负载均衡芯片可以显著提高系统的整体性能和响应速度,本文将详细介绍负载均衡芯片的原理、常见类型、实现方法以及在实际中的应用。
负载均衡芯片的原理
静态负载均衡
静态负载均衡是在系统启动时预先分配任务给各个处理单元,这种方法适用于任务数量和复杂度已知且变化不大的场景,在一个视频编码系统中,可以将不同的视频帧分配给不同的处理核心进行编码,这种方式简单直接,但缺乏灵活性,无法应对动态变化的工作负载。
动态负载均衡
动态负载均衡则是根据实时的系统状态和任务需求,动态地将任务分配给各个处理单元,这种方式更加复杂,但能够更好地适应变化的工作环境,常见的动态负载均衡策略包括任务池和工作窃取。
任务池
任务池是一种常见的动态负载均衡机制,线程从任务池中获取任务,完成后再获取新的任务,这种方法适用于任务数量和复杂度变化较大的场景。
工作窃取
工作窃取是另一种动态负载均衡机制,当某个处理单元完成任务后,可以从其他忙碌的处理单元的任务队列中“窃取”任务,以平衡负载,这种方法特别适用于异构任务和不确定的任务到达速率。
负载均衡芯片的实现方法和技术
线程池
线程池是一种常用的实现负载均衡的方法,通过预先创建一组线程,并将任务提交到任务队列中,线程从队列中获取任务并执行,线程池可以减少线程创建和销毁的开销,提高性能。
#include <iostream>
#include <thread>
#include <vector>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <functional>
class ThreadPool {
private:
std::vector<std::thread> workers;
std::queue<std::function<void()>> tasks;
std::mutex queue_mutex;
std::condition_variable condition;
bool stop;
public:
ThreadPool(size_t threads) : stop(false) {
for (size_t i = 0; i < threads; ++i) {
workers.emplace_back([this] {
while (true) {
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->queue_mutex);
this->condition.wait(lock, [this] { return this->stop || !this->tasks.empty(); });
if (this->stop && this->tasks.empty()) {
return;
}
task = std::move(this->tasks.front());
this->tasks.pop();
}
task();
}
});
}
}
~ThreadPool() {
{
std::unique_lock<std::mutex> lock(queue_mutex);
stop = true;
}
condition.notify_all();
for (std::thread &worker : workers) {
worker.join();
}
}
template<class F, class... Args>
void enqueue(F&& f, Args&&... args) {
{
std::unique_lock<std::mutex> lock(queue_mutex);
if (stop) {
throw std::runtime_error("enqueue on stopped ThreadPool");
}
tasks.emplace(std::bind(std::forward<F>(f), std::forward<Args>(args)...));
}
condition.notify_one();
}
};并行库
使用并行库如OpenMP和Intel TBB(Threading Building Blocks)也可以实现负载均衡,这些库提供了高级并行算法和数据结构,支持动态负载均衡和任务调度。
OpenMP
OpenMP是一种编译器指令集,可以让程序员简单地将串行代码转换为并行代码,编译器会自动管理线程的创建、调度和同步。
#include <omp.h>
#include <stdio.h>
int main() {
#pragma omp parallel for
for (int i = 0; i < 100; i++) {
printf("Thread %d is processing element %d
", omp_get_thread_num(), i);
}
return 0;
}Intel TBB
Intel TBB提供了一组高级并行算法和数据结构,支持动态负载均衡和任务调度,以下是一个简单的示例,展示了如何使用TBB进行并行计算。
#include <tbb/parallel_for.h>
#include <iostream>
void simple_parallel_algorithm() {
tbb::parallel_for(0, 100, [](int i) {
std::cout << "Thread " << tbb::this_thread::get_id() << " is processing element " << i << std::endl;
});
}分布式任务调度
在大规模系统中,可以使用分布式任务调度框架如MapReduce和Apache Spark来实现负载均衡,这些框架将任务分解成多个子任务,并分发到多个节点上执行,从而实现负载均衡。
MapReduce
MapReduce是一种编程模型,用于处理和生成大规模数据集,它将任务分为两个阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分成小块并分发到多个节点进行处理;在Reduce阶段,处理结果被汇总。
Apache Spark
Apache Spark是一个分布式计算框架,支持动态任务调度和负载均衡,它提供了丰富的API,用于数据处理和分析,以下是一个使用Spark进行并行计算的示例。
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("example").setMaster("local[4]")
sc = SparkContext(conf=conf)
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
result = distData.reduce(lambda a, b: a + b)
print(result)负载均衡芯片的应用案例
数据中心网络
在数据中心网络中,负载均衡芯片用于分配网络流量,确保各个服务器和网络设备均匀地分摊流量,避免某些设备过载,Barefoot Networks的Tofino芯片可以在交换机中实现高效的负载均衡功能,提升网络性能。
高性能计算(HPC)
在高性能计算集群中,负载均衡芯片用于分配计算任务,确保各个计算节点均匀地分摊工作负载,提高计算效率,Intel的Xeon Phi加速器使用负载均衡技术来优化计算任务的分配。
云计算平台
在云计算平台中,负载均衡芯片用于分配虚拟机和容器资源,确保各个物理服务器均匀地分摊工作负载,提高资源利用率,Amazon Web Services(AWS)使用负载均衡技术来优化其EC2实例的资源分配。
边缘计算设备
在边缘计算设备中,负载均衡芯片用于分配计算和存储任务,确保各个设备均匀地分摊工作负载,提高系统的响应速度和可靠性,AT&T在其生产网络中使用Tofino芯片来实现高效的负载均衡功能。
归纳与展望
负载均衡芯片在现代计算系统中扮演着至关重要的角色,通过合理的任务调度和资源分配,负载均衡芯片可以显著提高系统的性能和响应速度,随着技术的不断进步,负载均衡芯片将在更多的应用场景中得到广泛应用,如人工智能、物联网和5G通信等,随着可编程芯片的发展,负载均衡芯片将变得更加灵活和智能,能够更好地适应动态变化的工作环境和复杂的应用需求。
小伙伴们,上文介绍了“负载均衡芯片”的内容,你了解清楚吗?希望对你有所帮助,任何问题可以给我留言,让我们下期再见吧。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/23714.html