韩国云CDN如何提供全球覆盖的服务?

韩国云CDN如何提供全球覆盖的服务?
随着互联网的高速发展,数据传输和访问的速度已经成为了衡量一个网站或应用质量的重要标准,为了满足用户对于高速、稳定、安全的网络体验的需求,许多企业和个人都开始使用CDN(Content Delivery Network,内容分发网络)服务,韩国云CDN作为一家专业的CDN服务提供商,致力于为全球用户提供高品质的CDN服务,韩国云CDN是如何实现全球覆盖的呢?本文将从以下几个方面进行详细介绍。
1. 数据中心布局
为了实现全球覆盖,韩国云CDN在世界各地建立了多个数据中心,这些数据中心分布在亚洲、欧洲、北美等地区,形成了一个庞大的全球网络,通过这种分布式的布局策略,韩国云CDN可以确保用户在全球范围内都能获得较快的访问速度和稳定的服务。
2. 优化网络路由
韩国云CDN采用了智能的负载均衡技术,根据用户的地理位置和网络状况,自动选择最佳的路径进行数据传输,这样可以有效地减少数据在传输过程中的延迟,提高访问速度,韩国云CDN还采用了动态路由策略,根据网络状况实时调整数据传输路径,确保用户始终能够获得最优的网络体验。
3. 强化安全防护
网络安全是韩国云CDN非常重视的一个方面,为了保障用户数据的安全,韩国云CDN采用了多重安全防护措施,韩国云CDN对所有数据中心进行了严格的物理安全保护,确保数据中心内部的设备和数据不会受到外部威胁,韩国云CDN采用了先进的加密技术,对用户的数据进行全程加密传输,防止数据泄露,韩国云CDN还建立了完善的监控体系,实时监控网络状况和安全事件,及时发现并处理潜在的安全隐患。
4. 提供多样化的服务套餐
为了满足不同用户的需求,韩国云CDN提供了多种服务套餐供用户选择,用户可以根据自己的需求选择合适的套餐,享受相应的带宽、流量和功能,韩国云CDN还提供了灵活的计费方式,用户可以根据自己的实际使用情况支付费用,既方便又经济。
韩国云CDN通过数据中心布局、优化网络路由、强化安全防护以及提供多样化的服务套餐等策略,实现了全球覆盖的服务,这些优势使得韩国云CDN成为了众多企业和个人的信赖之选。
相关问题与解答:
1. 韩国云CDN支持哪些类型的服务?
答:韩国云CDN支持包括网站加速、下载加速、视频加速、动态加速等多种类型的服务,用户可以根据自己的需求选择合适的服务类型。
2. 韩国云CDN的计费方式有哪些?
答:韩国云CDN提供了包年包月、按流量计费等多种计费方式供用户选择,用户可以根据自己的实际使用情况选择合适的计费方式。
3. 如何申请使用韩国云CDN服务?
答:用户可以通过访问韩国云CDN官方网站(www.koreancloudcdn.com),在线提交申请表格,填写相关信息后提交即可,审核通过后,用户即可享受到韩国云CDN的服务。
4. 韩国云CDN是否支持自定义域名?
答:是的,韩国云CDN支持用户自定义域名,用户可以在申请服务时将自定义域名告知客服人员,审核通过后即可使用自定义域名访问加速服务。
相关文章

探索阿里CDN,性能、稳定性与全球覆盖的深度解析?,以疑问句的形式提出,旨在引导读者对阿里CDN的性能、稳定性以及其在全球范围的覆盖情况产生兴趣,并进一步阅读文章以寻找答案。
韩国云服务器哪家便宜(韩国云服务器哪家便宜好用)(韩国云服务公司)
韩国云服务器价格,韩国云服务器价格表2022年更新(韩国云服务公司)
韩国云计算技术的发展对韩国经济的影响如何?「韩国云计算技术的发展对韩国经济的影响如何」
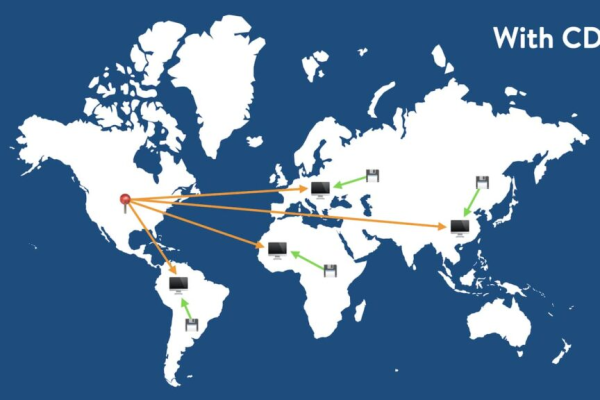
如何有效部署CDN以实现全球覆盖?
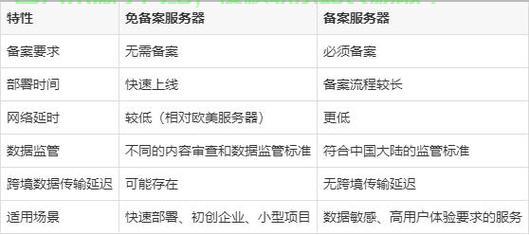
免备案服务器是否支持全球覆盖?
日本服务器直播的优势:高速稳定、卓越的画质表现、全球覆盖。「」

韩国云存储方案是否提供24/7技术支持?「韩国云存储方案是否提供24/7技术支持呢」








