上一篇
mysql如何筛选出重复数据
在MySQL中,可以使用 GROUP BY和 HAVING子句来筛选出重复数据。首先使用 GROUP BY对需要筛选的字段进行分组,然后使用 HAVING子句统计每组的数量,最后通过数量大于1的条件筛选出重复数据。,,示例代码:,,“ sql,SELECT column_name, COUNT(column_name),FROM table_name,GROUP BY column_name,HAVING COUNT(column_name) > 1;,“
在MySQL中,我们可以使用多种方法来筛选出重复的数据,下面是一种常见的方法:

1. 使用GROUP BY和HAVING子句
我们可以使用GROUP BY子句将数据按照某一列或多列进行分组,然后使用HAVING子句来筛选出那些具有相同列值的重复数据。
假设我们有一个名为students的表,其中包含学生的ID、姓名和班级信息,我们想要找出所有同名的学生。
查询语句
SELECT name, COUNT(name) as count FROM students GROUP BY name HAVING count > 1;
这个查询会返回一个结果集,其中列出了所有出现多次的学生姓名以及它们出现的次数。
2. 使用自连接
另一种方法是使用自连接来比较表中的数据,找出重复的数据,这种方法通常用于找出完全重复的行。
查询语句
SELECT a.* FROM students a, students b WHERE a.id <> b.id AND a.name = b.name AND a.class = b.class;
这个查询会返回所有与另一行在所有列上都相同的行。
相关问题与解答
Q1: 如何在MySQL中删除重复的数据?
A1: 可以使用DELETE语句结合JOIN或GROUP BY子句来删除重复的数据,具体方法取决于数据的结构以及你想要保留哪些行。
Q2: 如何防止MySQL中的数据重复?
A2: 可以通过设置唯一索引或者使用INSERT IGNORE或INSERT ... ON DUPLICATE KEY UPDATE语句来防止数据重复,也可以在应用层进行数据验证,确保不会插入重复的数据。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/235116.html
相关文章
-

以下几个疑问句标题可供选择,,如何查看 RDS for MySQL 数据库死锁日志及 MySQL 表格字段相关问题解析,RDS for MySQL 死锁日志怎么查看?与 MySQL 表格字段操作探讨,怎样查看 RDS for MySQL 数据库的死锁日志?关于 MySQL 表格字段的思考,RDS for MySQL 数据库死锁日志查看方法与 MySQL 表格字段研究,如何查看 RDS for MySQL 数据库死锁日志?对 MySQL 表格字段的分析
-
如何在ASP中筛选出重复的数据库记录?
-
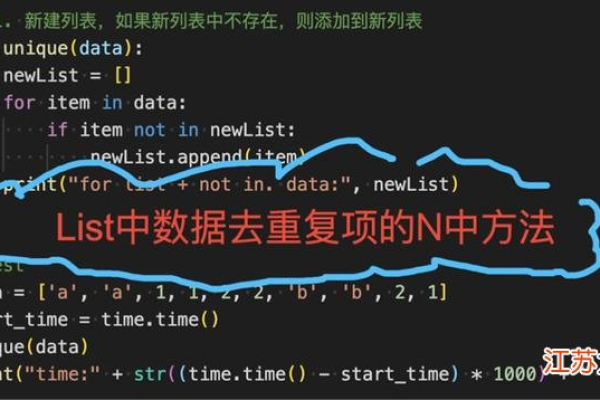
python查找列表重复项,如何筛选某一列的重复项(python查找列表中的重复值)
-
mysql恢复数据(mysql恢复数据库代码)(mysql 恢复数据)
-
ps怎么制作出重复图形,制作视频怎么重复画面(ps怎么把一个效果重复做)
-

如何利用MySQL识别并筛选出数据库中的重复来电信息?
-
access数据库如何筛选_列筛选
-
mysql筛选重复数据的方法是什么