
上一篇
大数据开源处理工具汇总
大数据处理工具众多,如Apache Hadoop提供分布式存储与计算,Spark快速处理大规模数据,Flink支持实时流处理,Hive适合SQL查询,Pig用于高级数据流转换。
Oracle上上月深耕大数据开源框架
小标题1:概述
Oracle是一家全球知名的数据库和软件公司,致力于提供全面的大数据解决方案。
上上月,Oracle发布了一项新的大数据开源框架,旨在帮助企业处理大规模的数据。
该框架提供了强大的数据处理能力和灵活的架构设计,以满足不同行业的需求。
小标题2:功能特点
分布式计算:该框架采用分布式计算技术,可以将数据处理任务分散到多个节点上并行执行,提高处理速度和效率。
数据存储:支持多种数据存储方式,包括传统的关系型数据库、NoSQL数据库以及分布式文件系统等,可以根据业务需求选择合适的存储方式。
实时处理:具备实时数据处理能力,可以快速响应业务需求,提供实时的数据洞察和分析结果。
容错性:具有良好的容错性,能够自动检测和处理节点故障,保证数据处理的稳定性和可靠性。
小标题3:应用场景
大数据处理:适用于大规模数据的处理和分析,如日志分析、数据挖掘等。
实时决策:可用于实时决策场景,如金融风控、智能交通等。
数据仓库:适用于构建高性能的数据仓库,提供快速的查询和报表生成能力。
单元表格:
| 功能特点 | 描述 |
| 分布式计算 | 将数据处理任务分散到多个节点上并行执行,提高处理速度和效率。 |
| 数据存储 | 支持多种数据存储方式,包括传统的关系型数据库、NoSQL数据库以及分布式文件系统等。 |
| 实时处理 | 具备实时数据处理能力,提供实时的数据洞察和分析结果。 |
| 容错性 | 自动检测和处理节点故障,保证数据处理的稳定性和可靠性。 |
| 应用场景 | 描述 |
| 大数据处理 | 适用于大规模数据的处理和分析,如日志分析、数据挖掘等。 |
| 实时决策 | 可用于实时决策场景,如金融风控、智能交通等。 |
| 数据仓库 | 用于构建高性能的数据仓库,提供快速的查询和报表生成能力。 |
备注:以上表格仅为示例,实际使用时可根据具体需求进行修改和扩展。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/233618.html
相关文章
-
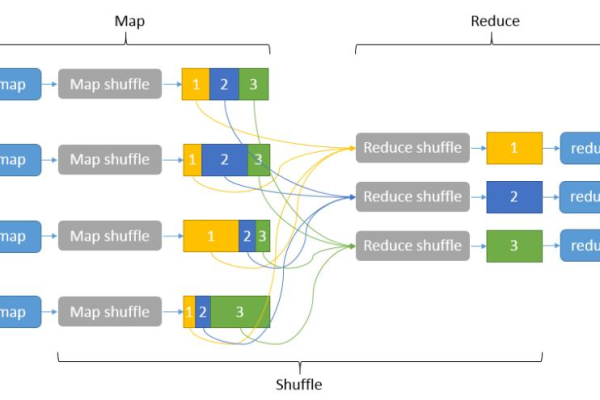
MapReduce 数据源处理机制是如何优化大数据作业的?
-

服务器15核通常指的是拥有15个中央处理器(CPU)核心的服务器。在多核处理器架构中,一个物理处理器可以包含多个核心,每个核心能够独立执行任务。因此,一个15核的服务器意味着它有15个这样的处理单元,可以并行处理任务,提高计算效率和多任务处理能力。,这样的服务器配置适合于需要高计算性能和并行处理能力的应用场景,例如大数据处理、科学模拟、复杂的数据分析、以及为大量用户提供服务的高性能网站和应用等。
-
测试用例管理工具开源_群组管理工具
-
access数据库管理工具_群组管理工具
-
客户管理工具_群组管理工具
-
asp.net网站管理工具 安全_群组管理工具
-
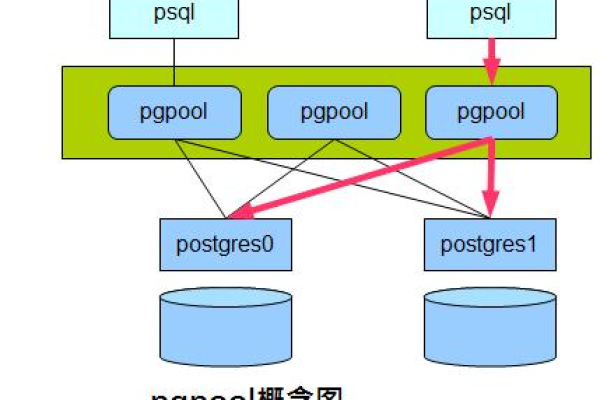
postgresql管理工具_群组管理工具
-
配置管理工具_群组管理工具
-

电子邮件管理工具_群组管理工具