
上一篇
hive 速度
Hive 速度取决于多个因素,如硬件配置、数据规模、查询优化等。优化 Hive 性能的方法包括:使用分区、索引、压缩等。
Hive的速度超越Oracle

随着大数据时代的到来,数据处理和分析的需求日益增长,传统的关系型数据库如Oracle在处理大规模数据时面临诸多挑战,而Hive作为一个基于Hadoop的数据仓库工具,逐渐展现出其优越的性能,本文将详细探讨Hive速度超越Oracle的原因。
Hadoop的优势
1、分布式存储:Hadoop采用HDFS作为分布式文件系统,将数据分散存储在多个节点上,提高了数据的可靠性和可扩展性。
2、并行计算:Hadoop的MapReduce框架支持并行计算,可以充分利用集群资源,提高数据处理速度。
3、容错性:Hadoop具有自动故障恢复功能,当某个节点出现故障时,可以自动将任务迁移到其他节点,保证数据处理过程的连续性。
Hive的优势
1、SQLlike查询语言:Hive提供了类似SQL的查询语言,使得熟悉SQL的用户可以轻松上手,降低了学习成本。
2、数据抽象:Hive将底层的MapReduce计算隐藏起来,用户只需关注数据表和查询语句,无需关心具体的计算过程。
3、兼容性:Hive兼容多种数据格式,如文本、CSV、JSON等,方便用户导入和导出数据。
4、可扩展性:Hive可以根据需求进行水平扩展,增加节点以应对不断增长的数据量。
Hive速度超越Oracle的原因
1、硬件成本:相较于Oracle的高硬件成本,Hadoop集群的搭建和维护成本较低,这使得Hive在处理大规模数据时具有较高的性价比。
2、数据处理能力:Hadoop的分布式存储和并行计算能力使得Hive在处理大规模数据时具有较高的性能,尤其是在数据分析和报表生成等场景下。
3、实时性:虽然Hive在实时数据处理方面略逊于Oracle,但对于大多数企业来说,离线数据处理已经足够满足需求,随着Spark等技术的发展,Hive的实时数据处理能力也在不断提升。
4、社区支持:Hive拥有庞大的开源社区,持续提供技术支持和优化建议,使得Hive在性能和稳定性方面得到了持续改进。
上文归纳
Hive在硬件成本、数据处理能力和社区支持等方面具有优势,使得其在处理大规模数据时的速度超越了Oracle,Hive并非适用于所有场景,对于实时数据处理和事务处理等场景,Oracle仍然是首选,企业在选择数据处理工具时,应根据自身需求进行权衡。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/232960.html
相关文章
-
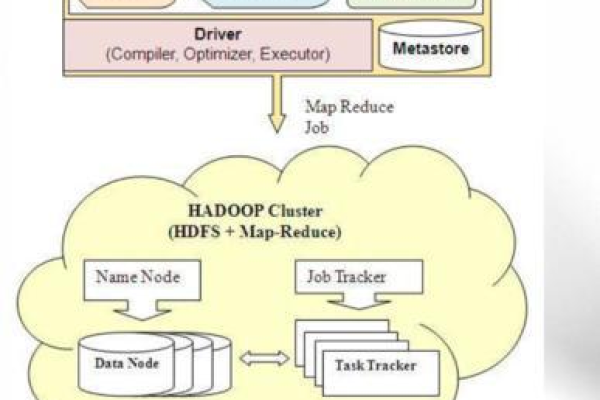
如何处理MapReduce和Hive中的故障,HiveServer与HiveHCat进程问题解析?
-
android maven plugin_使用jib-maven-plugin插件构建maven工程制作镜像
-
myeclipse maven_Maven,在MyEclipse中配置和使用Maven的最佳实践是什么?
-

腾讯云sqlserver(腾讯云sqlserver远程连接不上)(腾讯云sql server)
-
Ubuntu 安装 MySQL Server 提示 mysql-server : Depends: mysql-server-5.5
-

FileZilla Server是什么软件?FileZilla Server下载地址(filezillaserver是个什么软件)
-

windows中goldwave怎么降噪提高人声(goldwave怎么使用)(怎样用goldwave给人声降噪)
-
windows中goldwave如何把两个音乐合在一起(用goldwave)(goldwave怎么把两个音乐合在一起)
-
windows中goldwave如何去除音频中的噪音(不能使用goldwave实现的是)(利用goldwave可以去除声音文件中的杂音)