上一篇
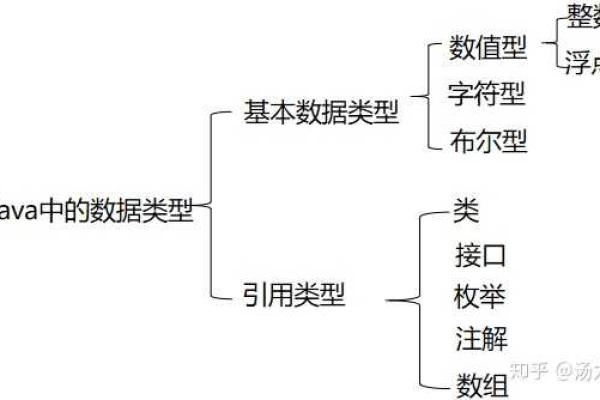
cassandra数据类型
Cassandra支持的数据类型包括:字符串、整数、浮点数、布尔值、时间戳、UUID、集合和地图等。
在Cassandra中设计数据模型以提高性能

1、选择合适的数据模型
面向列的存储:Cassandra是一个面向列的数据库,适合处理大量数据的查询和分析,将数据按照列进行组织可以提高读取和写入的性能。
避免过度规范化:过度规范化会导致大量的JOIN操作,影响性能,在设计数据模型时,应该尽量减少JOIN操作,避免不必要的数据冗余。
2、使用合适的数据类型
使用适当的数据类型可以减少数据的存储空间,提高性能,使用整数代替浮点数,使用字符串代替BLOB等。
注意数据类型的顺序对性能的影响,使用DECIMAL代替FLOAT可以减小存储空间,提高性能。
3、设计合理的索引
使用索引可以加快查询的速度,在设计数据模型时,应该根据查询需求合理地创建索引。
注意索引的选择和使用,过多的索引会增加写入操作的开销,降低性能,应该根据实际需求选择适当的索引。
4、考虑分区和分片策略
合理的分区和分片策略可以提高数据的分布性和并行性,从而提高性能。
根据数据的访问模式和查询需求来选择合适的分区键和分片策略,根据时间戳作为分区键可以提高按时间范围查询的性能。
5、优化写入操作
批量写入:使用批量写入可以减少网络开销和磁盘I/O操作,提高写入性能。
异步写入:对于一些对实时性要求不高的写入操作,可以使用异步写入来提高性能。
相关问题与解答:
问题1:在Cassandra中如何选择合适的数据模型?
答:选择合适的数据模型需要考虑以下几个方面:
数据的访问模式:根据数据的访问模式来选择合适的数据模型,如果需要频繁地进行按时间范围查询,可以考虑使用时间戳作为分区键的数据模型。
查询的需求:根据查询的需求来设计数据模型,避免过度规范化和JOIN操作。
数据的一致性要求:根据数据的一致性要求来选择合适的数据模型,如果需要强一致性保证,可以选择使用单个数据中心的数据模型。
问题2:在Cassandra中如何优化写入操作?
答:优化写入操作可以考虑以下几个方面:
批量写入:使用批量写入可以减少网络开销和磁盘I/O操作,提高写入性能,可以通过调整批量写入的大小来平衡性能和资源利用率。
异步写入:对于一些对实时性要求不高的写入操作,可以使用异步写入来提高性能,异步写入可以减少等待时间,提高系统的吞吐量。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/229422.html