上一篇
如何有效利用rlike工具提升文本处理效率?
rlike工具通过提供正则表达式匹配功能,可以有效提升文本处理效率。它允许用户快速检索、替换和抽取文本数据中的特定模式或信息,从而简化文本分析、数据清洗和信息提取等任务。使用rlike时,应结合具体需求设计合适的正则表达式,以优化 文本处理流程。
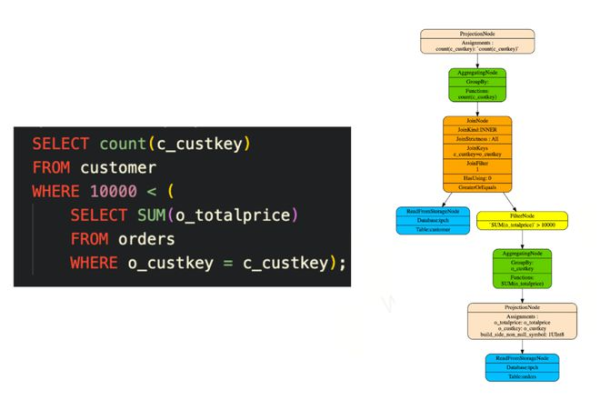
在数据库查询中,RLIKE 关键字的作用是不可或缺的,特别是在处理需要复杂模式匹配的数据集时。RLIKE 在MySQL和Hive等数据库系统中用于执行正则表达式模式匹配,其功能远强大于传统的LIKE 操作符,本文将详细解析RLIKE 的使用方式、语法结构以及实际应用示例,帮助读者深入理解并有效运用这一工具。

基本语法和定义
在MySQL中,RLIKE 关键字用于基于正则表达式的模式匹配,其基本语法是:SELECT column FROM table WHERE column RLIKE pattern;,这里,column 代表需要进行检查的列,table 是数据表的名称,而pattern 则是用于匹配的正则表达式模式。
与LIKE 相比,RLIKE 支持标准的正则表达式语法,如^,$,,?,| 等,这使得它能够执行更为复杂的匹配任务,例如在Hive中,虽然RLIKE 使用正则表达式提供更复杂的匹配功能,但也可以使用regexp 和notregexp 作为替代选项,这为开发者提供了更多的灵活性。
简单匹配示例
以一个简单的例子来说明RLIKE 的使用,假设有一个名为students 的表,包含学生的姓名和出生日期,如果要查找所有姓“Han”的学生,可以使用以下SQL语句:SELECT * FROM students WHERE name RLIKE '^Han';,这条语句将会返回所有名字以“Han”开头的学生记录。
高级匹配技术
RLIKE 的强大之处在于其处理复杂匹配需求的能力,如果我们要从一个包含电话号码的表中查找符合特定格式(如美国的电话号码格式)的所有记录,可以使用类似如下的表达式:SELECT * FROM table WHERE field RLIKE '[09]{3}[09]{3}[09]{4}';,这个表达式会匹配任何符合XXXXXXXXXX格式的电话号码。
使用场景与优势
在数据处理和分析领域,尤其是涉及到大量文本或需要特定格式校验的情况下,RLIKE 显示出其强大的功能,在进行日志文件分析、复杂的数据清洗任务或者需要从大型数据库中提取符合特定模式的记录时,RLIKE 可以极大地简化查询的复杂度和提高数据处理的效率。
相关FAQs
Q1: 使用RLIKE有什么性能考虑吗?
A1: 使用RLIKE 时,主要的性能考虑在于正则表达式的复杂度,复杂的正则表达式可能会导致查询响应时间增加,尤其是在处理大量数据时,合理设计正则表达式,并进行适当的索引优化是提升性能的关键措施。
Q2: RLIKE与传统的LIKE操作符有何不同?
A2:RLIKE 与LIKE 的主要区别在于匹配能力的复杂度。LIKE 主要用于简单的模式匹配,支持通配符如百分比(%)和下划线(_),相比之下,RLIKE 支持完整的正则表达式语法,能够执行更为复杂的匹配任务,如匹配特定格式的字符串、进行多条件选择等。
通过上述详细解析,可以看出RLIKE 是一个功能强大的工具,适用于处理各种复杂的模式匹配需求,不论是数据分析人员还是数据库管理员,掌握RLIKE 的使用都是提升工作效率的重要手段。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/222646.html