

上一篇
Redis如何实现数据库读写分离详解
Redis通过主从架构实现读写分离,主数据库负责写操作,而从数据库承担读操作,提高并发吞吐和负载能力。在特定场景下,可适当牺牲一致性以优化性能,存在星型复制和链式复制两种数据同步方式。此机制适用于读多写少的业务场景,能有效节约成本并提升系统效率。
深入解析Redis数据库读写分离实现:原理与实践
技术内容:
在当今互联网时代,数据的高并发读写已经成为一种常态,为了应对这种挑战,许多企业采用了分布式数据库技术,其中Redis作为一款高性能的键值对存储系统,被广泛应用于缓存、消息队列等场景,随着业务量的不断增长,单一Redis实例逐渐无法满足海量数据的高并发读写需求,此时,数据库读写分离技术应运而生,本文将详细介绍Redis如何实现数据库读写分离,包括原理和实践。
Redis读写分离原理
1、基本概念
读写分离是指将数据库的读操作和写操作分开,分别由不同的数据库实例来处理,写操作由主数据库(Master)处理,读操作由从数据库(Slave)处理,通过这种方式,可以将数据库的负载均衡到多个实例上,提高系统整体性能。
2、Redis主从复制
Redis实现读写分离的核心是主从复制(Replication),主从复制是指将一个Redis主数据库的数据复制到一个或多个从数据库,主数据库负责处理写操作,而从数据库负责处理读操作,当主数据库的数据发生变化时,这些变化会被同步到从数据库。
主从复制的原理如下:
(1)从数据库启动时,会向主数据库发送SYNC命令,请求同步数据。
(2)主数据库收到SYNC命令后,开始执行BGSAVE命令,将当前数据库的数据快照保存到磁盘。
(3)主数据库将数据快照发送给从数据库。
(4)从数据库接收数据快照,并加载到内存中。
(5)主数据库将此后执行的所有写操作命令发送给从数据库,保证主从数据库数据一致。
3、读写分离的优势
(1)提高读操作性能:将读操作分散到多个从数据库,提高系统处理高并发读请求的能力。
(2)提高写操作性能:主数据库负责处理写操作,减轻了单个数据库实例的压力。
(3)故障转移:当主数据库发生故障时,可以从从数据库中选举一个新的主数据库,继续提供服务。
Redis读写分离实践
1、搭建主从复制环境
(1)安装Redis:分别在主数据库和从数据库服务器上安装Redis。
(2)配置主数据库:修改主数据库的配置文件redis.conf,设置如下参数:
bind 0.0.0.0
port 6379
daemonize yes
appendonly yes
(3)配置从数据库:修改从数据库的配置文件redis.conf,设置如下参数:
bind 0.0.0.0
port 6380
daemonize yes
appendonly yes
slaveof <主数据库IP> 6379
(4)启动主从数据库:分别启动主数据库和从数据库。
2、实现读写分离
在应用程序中,通过以下方式实现读写分离:
(1)写操作:直接连接主数据库,执行写操作。
(2)读操作:连接从数据库,执行读操作。
可以使用如下伪代码表示:
// 初始化主从数据库连接
MasterRedis = new RedisClient("主数据库IP", 6379);
SlaveRedis = new RedisClient("从数据库IP", 6380);
// 写操作
MasterRedis.Set("key", "value");
// 读操作
string value = SlaveRedis.Get("key");
本文详细介绍了Redis数据库读写分离的原理与实践,通过主从复制技术,Redis实现了读写分离,有效提高了系统在高并发场景下的性能,在实际应用中,根据业务需求,我们可以灵活地配置主从数据库的数量和比例,以达到最佳的性能表现,需要注意的是,在实现读写分离时,要确保主从数据库数据的一致性,避免因数据不一致导致的业务问题。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/215434.html
相关文章
-
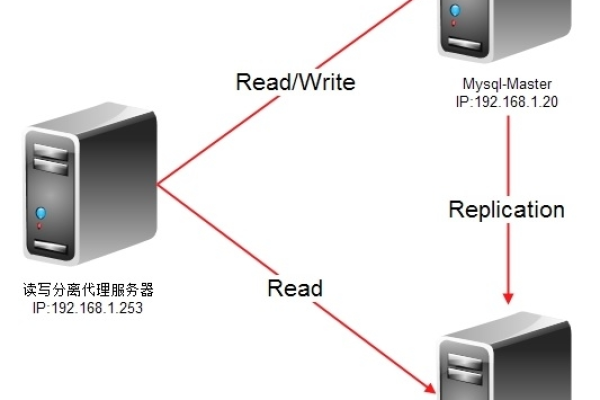
读写分离模式_设置读写分离路由模式
-
关于闪存(Flash Memory)的读写原理,一个原创且具有疑问性质的标题可以是,,Flash存储是如何实现数据读写的?,分析该疑问句标题,,以一个疑问的形式提出,旨在探讨闪存技术中数据读写的基本原理和机制。它涵盖了用户可能对闪存读写过程产生的好奇和不解,同时也为读者提供了一个深入了解闪存技术的切入点。通过解答这个问题,文章可以详细介绍闪存的工作原理、读写过程中的电子运动、以及数据如何在闪存中被存储和检索等关键信息。
-
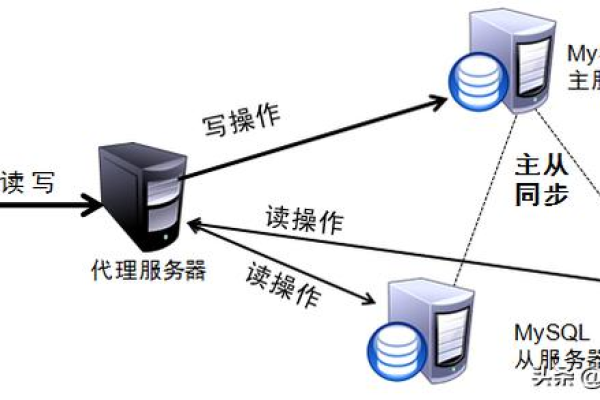
如何实现MySQL数据库的分离与附加,并配置数据库代理进行读写分离?
-
如何实现MapReduce与Redis的读写分离?
-
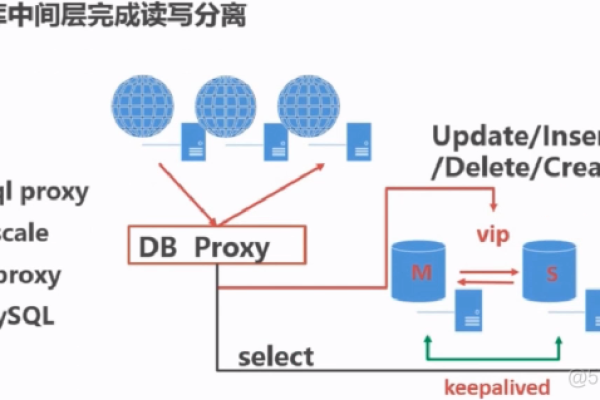
如何实现MySQL数据库的分离与GaussDB (for MySQL) 读写分离的最佳实践?
-
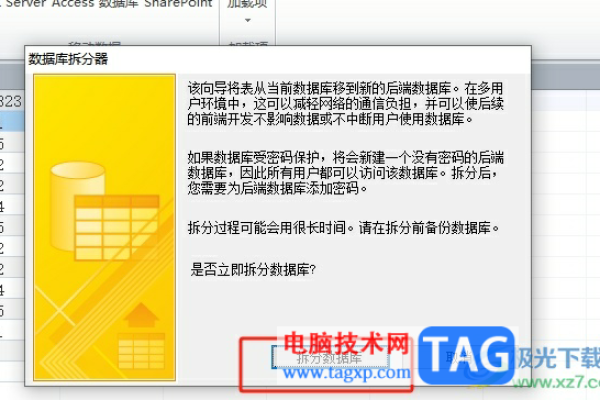
access 分离数据库_数据库代理(读写分离)
-
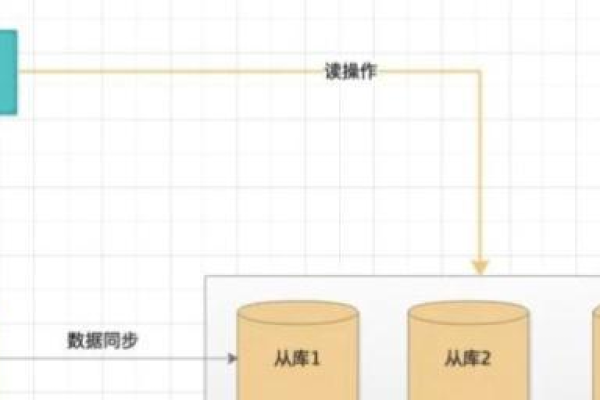
如何实现数据库的读写分离与副本集高可用性?
-
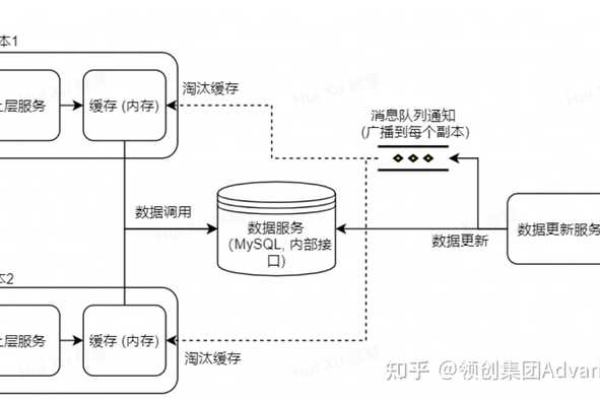
如何在mui框架中优化MySQL数据库的读写性能以实现高效的数据库读写操作?








