DMS数据管理折扣

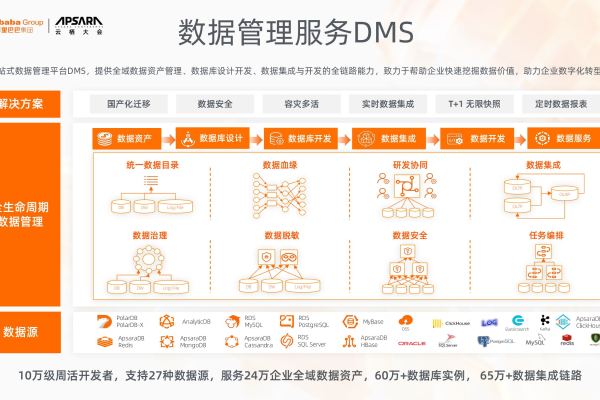
DMS数据管理折扣DMS(Data Management Service)是阿里云推出的一站式
数据管理平台,提供数据库实时开发、数据集成与开发等全链路能力。在企业级应用中,DMS通过高效的数据备份、数据传输和安全管理功能,确保数据的可靠性和安全性。其强大的实时数据流技术,支持秒级延迟的数据处理,满足业务对实时性的高要求。DMS还具备敏感数据识别和防护、SQL审核等功能,保障数据操作的安全性和合规性。
1、折扣活动:华为云DMS会不定期推出打折优惠活动,如在2024年,新用户购买指定配置的DMS服务可享受包年包月折扣,具体折扣力度因不同的配置和套餐而异。

2、计费方式:华为云DMS提供了多种计费方式,包括包年包月(预付费)和按量付费(后付费),包年包月适合长期需求,购买时长越长,折扣越多;按量付费则是先使用后付费,适合短期需求,用完可立即释放实例,节省费用。
3、存储包和网络包:阿里云DMS还推出了存储包和网络包,这是一种预付费资源包,可以抵扣部分不再计费,仅超出部分将按使用量或按天计费,如果用户在RDS控制台、PolarDB控制台产生了较大的存储费用和网络费用,推荐使用存储包和网络包,相比按量付费更加优惠,且购买的容量越大,折扣力度越大。

华为云DMS的折扣活动为用户提供了更多的选择和便利,用户可以根据自己的需求和使用情况选择合适的折扣方案和计费方式,以降低数据管理的成本。

本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/2095.html