第1张")
上一篇
使用vps linux记录蜘蛛爬取的方法简介 (vps linux怎样记录蜘蛛爬取)
使用VPS Linux记录蜘蛛爬取的方法是通过配置服务器日志和Web应用日志,结合日志分析工具来监控和记录爬虫活动。
使用VPS Linux记录蜘蛛爬取的方法简介
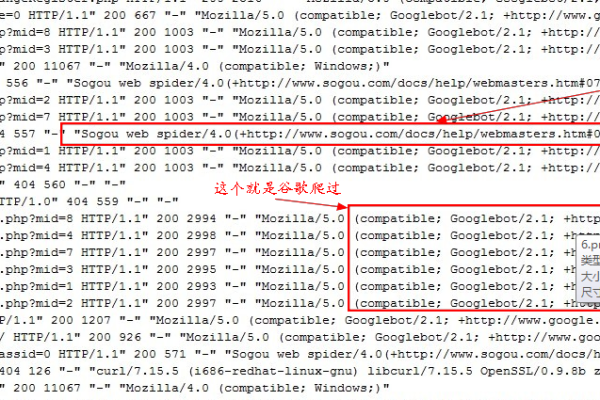
在互联网的世界里,网络爬虫(也被称为蜘蛛)是搜索引擎用来索引网页内容的程序,它们按照一定的规则自动访问网站并收集信息,对于网站管理员而言,了解哪些蜘蛛访问了网站以及它们的活动模式对于SEO(搜索引擎优化)和网站性能分析至关重要,本文将介绍如何在VPS(虚拟私有服务器)上使用Linux操作系统记录这些蜘蛛的爬取行为。
配置服务器日志
大多数网站服务器软件,如Apache或Nginx,都允许你通过配置文件来设置日志记录,通常,你可以通过编辑服务器配置文件来启用或调整访问日志的详细程度。
1、Apache服务器
在Apache中,你需要编辑httpd.conf文件或相应的虚拟主机配置文件,确保以下指令被包含:
CustomLog /var/log/apache2/access.log combined
这会记录所有请求到/var/log/apache2/access.log文件中,包括爬虫的信息。
2、Nginx服务器
对于Nginx,编辑nginx.conf文件或特定站点的配置文件,确保access_log指令被正确设置:
access_log /var/log/nginx/access.log;
分析日志文件
一旦日志被正确配置,你就可以开始分析这些日志来识别爬虫的活动,你可以使用文本编辑器手动检查,但更推荐使用日志分析工具,如awstats或webalizer。
安装awstats后,你可以在命令行中使用以下命令生成报告:
awstats -f /var/log/apache2/access.log
这将生成一个包含各种有用信息的HTML报告,比如访问最多的页面、爬虫的活动等。
使用防火墙规则
在某些情况下,你可能想要阻止特定的不良爬虫或减少它们对你服务器的影响,在这种情况下,你可以使用iptables(Linux上的防火墙工具)来限制特定IP地址的访问。
如果你发现一个特定的爬虫IP不断访问你的网站,你可以添加以下规则来阻止它:
iptables -A INPUT -s <SPIDER_IP> -j DROP
利用第三方服务
除了自己配置日志记录和分析外,你还可以利用第三方服务来帮助你跟踪和管理爬虫的活动,Google Search Console可以帮助你理解Googlebot(Google的爬虫)是如何爬取你的网站的。
相关问题与解答
Q1: 我怎样才能知道我的网站是否被网络爬虫频繁访问?
A1: 通过检查服务器的访问日志,你可以查看到所有对网站的请求,包括来自爬虫的请求,如果日志中出现大量来自已知爬虫IP的请求,那么可以判断网站正受到频繁的爬取。
Q2: 我应该担心爬虫对我的网站造成负担吗?
A2: 大多数情况下,爬虫对网站的影响是有限的,如果某个爬虫过于活跃或者有反面行为,确实可能对服务器资源造成压力,监控爬虫的行为并根据需要采取措施是明智的。
Q3: 我可以使用哪些工具来分析服务器日志?
A3: awstats和webalizer是两个常用的日志分析工具,还有像GoAccess、Logstash和Graylog等更先进的工具可供选择。
Q4: 如何区分正常用户和网络爬虫的服务器日志?
A4: 通常,网络爬虫的IP地址是可识别的,并且它们的访问模式(如请求频率)与普通用户不同,许多爬虫会在请求头中标识自己,例如使用"User-Agent"头部字段,通过检查这些特征,你可以区分出爬虫的活动。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/207638.html