如何合理设置MapReduce作业中的Reduce数量以优化性能?

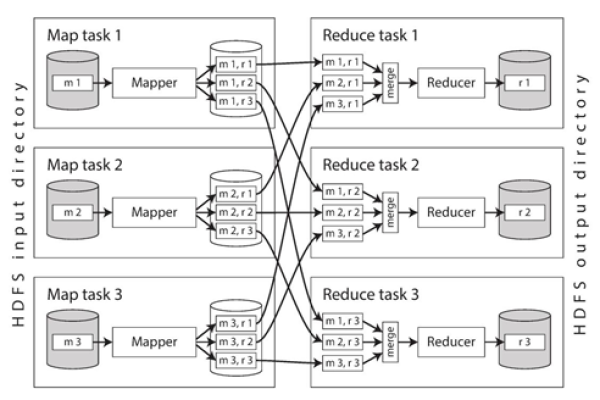
在MapReduce框架中,恰当地设置Reduce任务的数量是至关重要的,这个设置直接影响着作业的执行时间及资源的利用效率,以下是具体探讨如何合理配置Reduce数量:
1、Reduce数量的影响
性能影响:默认情况下,Reduce任务的数量被设置为1,这在处理大量数据的情况下可能引起性能瓶颈,因为所有数据都必须通过一个单一的Reduce任务进行处理,延迟了数据处理速度。
资源利用:如果设置的Reduce数量过多,可能会导致集群资源的过载和浪费,每个Reduce任务都会占用一定的系统资源,包括CPU、内存和网络带宽。
完成时间:理想的Reduce数量应该能够使得整个数据处理过程的时间最短,这需要考虑到数据的分布、节点的处理能力以及网络的延迟等因素。
2、决定Reduce数量的因素
节点数量:在Hadoop集群中,节点的数量是决定并行度的重要因素,更多的节点意味着可以同时运行更多的Reduce任务,从而提高处理速度。
数据大小:输入数据的大小也会影响理想的Reduce数量,处理大量数据时,增加Reduce数量有助于提升处理速度和缩短作业完成时间。
资源限制:每个TaskTracker可以运行的reduce任务数量是有限制的(由mapred.tasktracker.reduce.tasks.maximum设定),实际可用的资源会影响Reduce任务的最优数量。
3、设置方法与计算
简易公式:一种常用的计算Reduce数量的方法是使用0.95乘以节点数与每个节点可运行的最大Reduce任务数的乘积,这可以确保大多数节点都能够参与到计算中,同时避免资源过度使用。
进阶调整:对于处理能力强、网络条件好的集群,可以考虑使用1.75倍的规则,即节点数与每节点最大Reduce任务数的乘积再乘以1.75,这样,一些节点在完成第一轮Reduce任务后可以开始第二轮,从而更充分地利用资源。
4、优化与调整策略
监控与调整:初始设置后,应密切监控MapReduce作业的运行状态和系统资源使用情况,根据监控结果适时调整Reduce任务的数量,以找到最佳平衡点。
考虑数据与算法特性:不同数据集和算法对资源的需求不同,应根据具体的应用场景和数据特性来微调Reduce任务的数量。
了解和合理设置MapReduce中的Reduce数量是优化Hadoop性能的关键步骤之一,通过合理的设置可以减少作业执行时间,提高资源利用率,从而有效支持大规模数据处理需求,实际操作中,应根据集群的实际状况和作业的具体需求进行调整,以达到最佳的性能表现。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11