上一篇
Flink CDC里从pg库采集cdc数据,flink程序断了之后,为啥不能指定从断的地方重新消费?
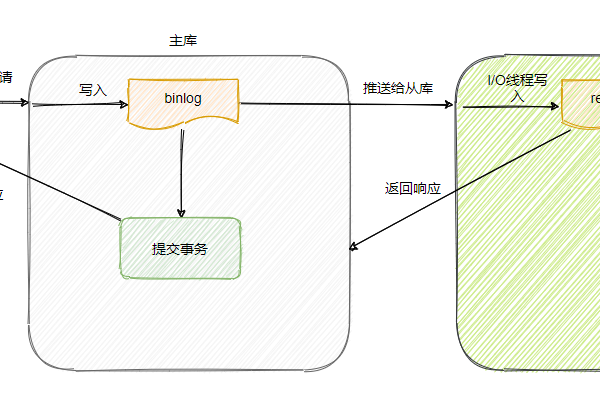
在Flink CDC(Change Data Capture,变化数据捕获)中,当从PostgreSQL数据库采集CDC数据时,如果Flink程序中断,不能直接从断点处重新消费的原因主要有以下几点:
1、检查点机制:Flink通过周期性的检查点来保证容错性,检查点包括了状态的快照以及源位置的信息,如果检查点成功完成,那么在发生故障时可以从最近的检查点恢复,如果检查点没有成功完成,或者在检查点之后发生了故障,那么系统无法知道确切的消费位置。
2、事务日志限制:PostgreSQL的事务日志通常不会无限期保留,它们会被定期清理或删除,这意味着一旦Flink程序断开连接,并且超过了事务日志的保留期限,就无法再从断点处重新读取数据。
3、一致性保证:Flink CDC设计为保证一致性而非实时性,这意味着它更注重于确保数据的准确无误,而不是实时处理每一条记录,即使程序中断,也不会尝试从确切的断点恢复,而是等待下一个检查点或者从头开始。
4、数据源的设计:Flink CDC的数据源设计可能不支持断点续传,这取决于具体的数据源实现和配置,Kafka等消息队列系统可以配置为支持从特定的偏移量开始消费,但并非所有数据源都提供这样的功能。
为了尽可能减少数据丢失或重复处理的风险,可以采取以下措施:
增加检查点的频率:通过减少检查点间隔,可以减少数据丢失的可能性。
使用外部存储:将检查点存储在外部可靠的存储系统中,如HDFS或S3,以确保检查点的持久性。
调整事务日志保留策略:根据需要调整PostgreSQL的事务日志保留时间,以便Flink有足够的时间处理和恢复。
相关问答FAQs:
Q1: Flink CDC能否保证完全的实时性?
A1: Flink CDC主要设计目标是保证一致性,而不是实时性,这意味着它可能会牺牲一些实时性来确保数据处理的准确性,它不保证在程序中断后能够立即从断点处恢复数据处理。
Q2: 如果我想在Flink CDC中实现断点续传,应该如何操作?
A2: 要实现断点续传,首先需要确保你的数据源支持这一特性,对于PostgreSQL,你可能需要结合Flink的检查点机制和事务日志保留策略来实现,你还可以考虑使用其他支持断点续传的数据源,如Kafka,配合Flink的特定连接器来实现这一功能。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/207128.html