如何配置MySQL以允许远程工具安全地连接数据库?

在数据库管理及应用中,允许工具连接MySQL数据库是一个重要的配置需求,本文将深入探讨如何设置MySQL以允许包括无线演示连接在内的远程连接,确保网络中的其他设备或应用能够顺利访问数据库资源,我们将介绍**修改配置文件、授权用户访问及防火墙设置等**关键步骤,以实现高效安全的数据库连接。
1. **配置文件的修改
**理解配置文件作用**:MySQL的配置文件通常是my.cnf或my.ini,它决定了MySQL服务运行时的多项参数,包括绑定地址和端口号,为了使数据库服务能被外部IP地址访问,需要编辑此文件以调整相关设定。
**修改bindaddress**:默认情况下,MySQL可能仅监听localhost(127.0.0.1),通过更改bindaddress为0.0.0.0,可以使MySQL服务器监听所有IP地址,从而接受任何网络接口的连接请求。
**配置文件的位置**:在Linux系统中,配置文件通常位于/etc/mysql/my.cnf或/etc/my.cnf,使用文本编辑器如nano进行编辑时,需要相应的管理员权限,如使用sudo nano /etc/mysql/my.cnf命令。
**配置文件的常见设置项**:除bindaddress外,还应检查配置文件中的其他相关设置,如端口号(port)设置,以确保没有使用非标准端口导致连接问题。
2. **授权用户访问
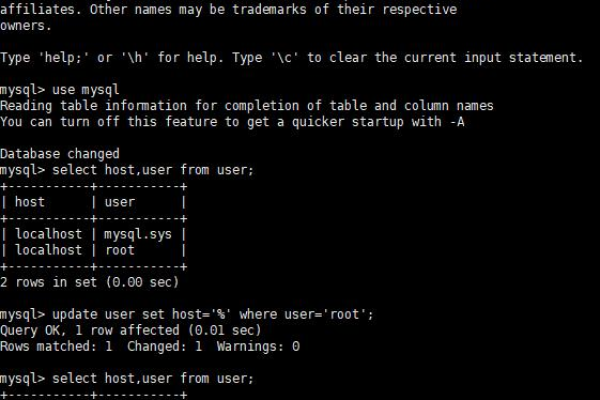
**直接修改用户数据**:登录MySQL后,可以通过更新user表中的host字段,将已有用户的访问权限从’localhost’更改为’%’,或者指定为需要访问的特定IP地址。
**添加新用户记录**:作为另一种方法,您可以在user表中新增一条记录,其host项设置为’%’或特定的IP地址,并为其授予相应权限,从而实现远程访问。
**使用GRANT命令**:通过执行GRANT命令,可以精确控制用户在特定数据库上的访问权限。“GRANT ALL PRIVILEGES ON database.* TO ‘user’@’%’ IDENTIFIED BY ‘password’;”允许用户从任何地点访问特定数据库。
**刷新权限**:修改了用户权限或添加新用户后,需要执行FLUSH PRIVILEGES命令,使得更改立即生效而无需重启服务。
**用户的安全实践**:应限制数据库的用户权限,遵循最小权限原则,仅提供必要的权限以降低安全风险。
3. **防火墙设置
**理解防火墙的作用**:数据库服务器的防火墙用于保护系统免受未经授权的访问,在允许远程连接时,必须配置防火墙以放行MySQL所使用的端口,通常为3306。
**添加例外端口**:在系统防火墙设置中添加一个例外规则,允许通过3306端口的流量,这确保了远程工具或应用在尝试通过该端口连接时不会受到阻拦。
**命令与图形界面**:在Linux系统中,可以使用iptables命令来设置防火墙规则,Windows系统中通常通过Windows防火墙的图形界面来配置。
**测试防火墙设置**:更改后,应从远程主机测试端口是否已正确打开,可以使用telnet或nc等工具检查端口的可访问性。
4. **服务管理与重启
**重启MySQL服务**:某些设置更改后需要重启MySQL服务才能生效,这可以通过service mysqld restart在Linux上或通过相应的服务管理工具在Windows上完成。
**使用系统ctl工具**:在某些系统中,可以使用systemctl来控制MySQL服务的启动、停止和状态检查,如systemctl restart mysqld。
**确认服务状态**:重启服务后,应检查MySQL服务的状态确保其正常运行,使用systemctl status mysqld或类似命令可以查看当前服务状态。
**日志文件检查**:重启后检查MySQL的日志文件,可以发现潜在的启动或运行错误,及时进行修正。
5. **安全性增强
**使用SSL/TLS连接**:为了保护数据传输过程中的安全,建议使用SSL/TLS加密客户端与数据库服务器之间的连接,这需要在MySQL配置文件中进行相应设置,并正确配置客户端。
**定期更新及打补丁**:保持MySQL服务器的定期更新和打补丁是保护系统安全的重要措施,可以减少被已知安全破绽攻击的风险。
**使用防火墙和IDS系统**:除了基本的防火墙设置外,考虑使用更复杂的安全系统如载入检测系统(IDS)来监控和分析网络流量,提前发现异常行为。
**实行访问控制和审计**:实施访问控制策略,确保只有授权用户才能访问数据库,同时设置审计日志,跟踪对所有敏感数据的访问和操作。
在实际操作中,还需要注意一些额外的细节,在修改配置文件时,应做好备份以便需要时恢复;在授权访问时,避免使用root账户进行日常操作,而是创建具有适当权限的用户账户;在开启远程访问后,定期检查和审计数据库活动,防止未授权访问等。
为您提供一些实用问答内容,以解答常见的相关问题。
### **FAQs
Q1: 为什么修改配置文件后无法立即看到更改效果?
A1: 修改配置文件后,通常需要重启MySQL服务使更改生效,这是因为MySQL在启动时读取配置文件的内容,并在运行期间不再检查这些文件的变化,任何对配置文件的修改都需要通过重启服务来重新加载配置。
Q2: 如何确保我的数据库连接是安全的?
A2: 为确保数据库连接的安全性,你可以采取以下几个措施:使用SSL/TLS加密客户端与服务器之间的连接;限制数据库用户的权限,按照最小权限原则操作;保持软件的更新和打补丁;利用防火墙和其他安全工具如IDS来监控和保护你的数据库不受未授权访问和其他威胁的侵害。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11