
上一篇
有用Flink CDC 3.0.1读取Oracle 19C PDB成功的吗?
使用Flink CDC 3.0.1读取Oracle 19C PDB的实践

在现代数据架构中,实时数据处理的需求日益增长,为此,Apache Flink作为一个开源流处理框架,提供了对变更数据捕获(Change Data Capture, CDC)的支持,CDC技术使得系统能够捕捉数据库中的变更事件,并即时将这些事件传递给下游系统进行处理,Flink CDC便是基于这一概念的实现,它能够与多种数据库配合工作,包括Oracle。
Oracle Database 19c是Oracle公司推出的一个重大版本更新,引入了多项新特性,如可插拔数据库(Pluggable Databases, PDB)等,PDB允许在一个Oracle容器数据库(CDB)内创建多个独立的数据库实例,每个实例可以有自己的用户、配置和数据,但共享同一个Oracle实例和存储资源。
本文将探讨如何使用Flink CDC 3.0.1版本来读取Oracle 19C PDB中的数据。
环境准备
在使用Flink CDC连接Oracle 19C PDB之前,需要确保以下条件得到满足:
1、安装并配置好Oracle 19C数据库,并创建PDB。
2、安装并设置好Apache Flink集群。
3、下载Flink CDC 3.0.1的Jar包或通过Maven/Gradle添加依赖。
4、确保网络连接畅通,Flink集群能够访问Oracle 19C数据库服务。
Flink CDC配置
要使用Flink CDC连接到Oracle 19C PDB,需要进行一些特定的配置,以下是配置步骤概览:
1、定义Flink的StreamExecutionEnvironment。
2、使用DataStream API或Table API创建源表(Source Table)。
3、指定Oracle 19C PDB的连接信息,包括JDBC URL、用户名和密码。
4、配置Flink CDC的扫描模式,例如是否从最早的数据开始捕获。
5、启动Flink作业,并监控数据的捕获过程。
示例代码
以下是一个使用Flink CDC读取Oracle 19C PDB的Java代码示例:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.jdbc.JdbcCatalog;
import org.apache.flink.table.data.Row;
import org.apache.flink.types.Row;
public class FlinkCDCOracleExample {
public static void main(String[] args) throws Exception {
// 创建Flink执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 注册JDBC目录
String name = "mycatalog";
String defaultDatabase = "mydatabase";
String username = "user";
String password = "password";
String baseUrl = "jdbc:oracle:thin:@localhost:1521/ORCL";
String driverClassName = "oracle.jdbc.driver.OracleDriver";
JdbcCatalog jdbcCatalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl);
tableEnv.registerCatalog("mycatalog", jdbcCatalog);
tableEnv.useCatalog("mycatalog");
tableEnv.executeSql("CREATE TABLE mysource ( ... ) WITH ( ... )"); // 创建源表
// 读取数据并打印
Table result = tableEnv.sqlQuery("SELECT * FROM mysource");
DataStream<Row> rowDataStream = tableEnv.toRetractStream(result, Row.class);
rowDataStream.print();
// 执行作业
env.execute("Flink CDC Oracle Example");
}
}
注意:上述代码中的...需要替换为具体的表结构和选项。
监控和调试
当Flink CDC作业运行起来后,可以使用Flink的Web UI来监控作业的状态和性能指标,如果遇到问题,可以查看日志文件或者使用Flink的调试工具进行排查。
相关问答FAQs
Q1: Flink CDC支持Oracle 19C哪些特性?
A1: Flink CDC主要支持捕获DML(插入、更新、删除)操作,对于DDL(数据定义语言)变更可能需要额外的处理,对于Oracle 19C特有的特性如PDB,Flink CDC能够正常识别并捕获其中的数据变更,但需要注意连接字符串和认证方式的正确性。
Q2: 如何处理Flink CDC在读取Oracle PDB时出现的性能瓶颈?
A2: 如果遇到性能瓶颈,可以从以下几个方面进行优化:
检查并优化Flink作业的配置,比如并行度、缓冲区大小等。
确保网络带宽足够,减少网络延迟。
优化数据库查询效率,避免全表扫描等低效操作。
考虑增加更多的Flink作业节点以分散负载。
定期清理不再需要的旧数据,以减少数据库的压力。
以上内容涵盖了使用Flink CDC 3.0.1读取Oracle 19C PDB的基本流程,包括环境准备、配置、示例代码以及监控和调试的建议,希望能够帮助用户成功实施Flink CDC与Oracle 19C PDB的集成。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/200778.html
相关文章
-
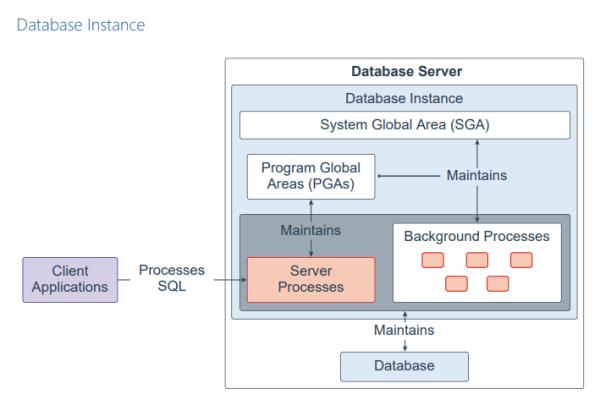
建立在Oracle Trustef Oracle数据库的基础上构建未来倚赖Oracle Trustef Oracle数据库的Oracle DB
-
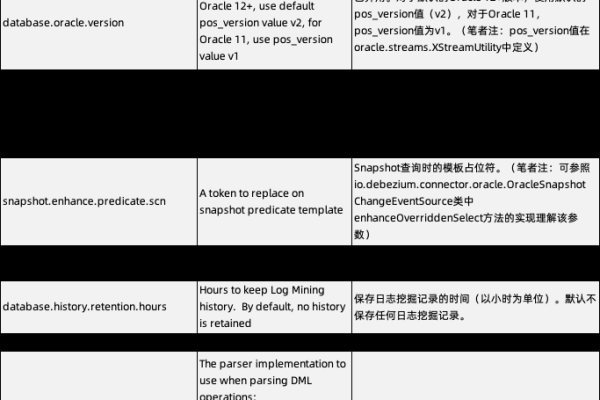
Flink CDC里根据官网oracle cdc抄下来,oracle拉数据1条1条的来,为啥这么慢?
-
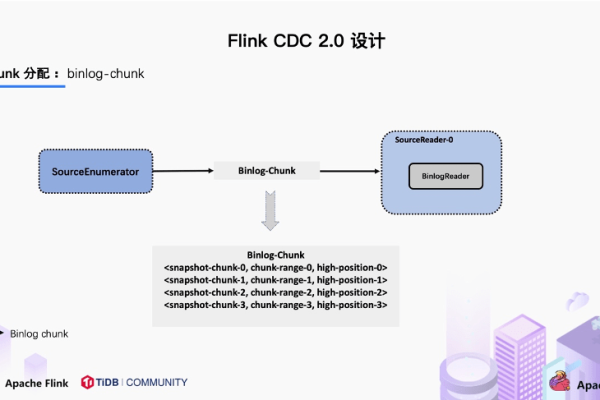
Flink CDC里从pg库采集cdc数据,flink程序断了之后,为啥不能指定从断的地方重新消费?
-
Flink CDC里oracle-cdc 使用 xstream ,为啥提交任务到 yarn 上报错?
-
flink cdc3.0.1连接到oracle 但是读取不到数据怎么办?
-
flinkcdc 3.0支持flink 1.19吗?
-
请教下 还是用flink cdc去读取的日志 这块有什么好的方法去获取数据的状态吗?
-

Flink CDC里flink1.17写doris的代码怎么做?








