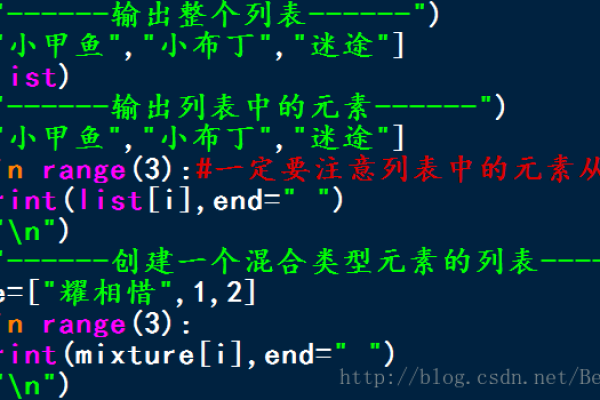
Python中的内置函数用来返回序列中的最大元素

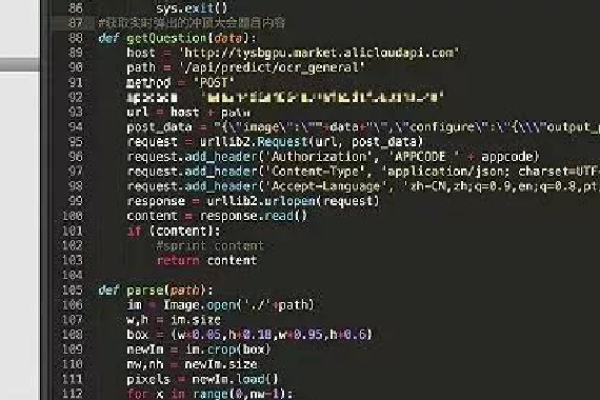
在Python中,有一些内置函数可以帮助我们从互联网上获取最新内容,这些函数包括urllib.request.urlopen()、requests.get()等,下面我将详细介绍如何使用这些函数来获取网页内容。
使用urllib.request.urlopen()函数
urllib.request.urlopen()函数是Python标准库中的一个内置函数,可以用来打开URL并获取其内容,使用方法如下:
1、需要导入urllib.request模块:
import urllib.request
2、使用urlopen()函数打开URL:
response = urllib.request.urlopen('https://www.example.com')
3、读取网页内容:
content = response.read()
4、将获取到的内容转换为字符串:
content_str = content.decode('utf8')
5、打印网页内容:
print(content_str)
完整的代码示例:
import urllib.request
response = urllib.request.urlopen('https://www.example.com')
content = response.read()
content_str = content.decode('utf8')
print(content_str)
使用requests.get()函数
requests.get()函数是一个第三方库,需要先安装requests库,安装方法如下:
pip install requests
安装完成后,可以使用requests.get()函数来获取网页内容,使用方法如下:
1、需要导入requests模块:
import requests
2、使用get()函数获取网页内容:
response = requests.get('https://www.example.com')
3、读取网页内容:
content = response.text
4、打印网页内容:
print(content)
完整的代码示例:
import requests
response = requests.get('https://www.example.com')
content = response.text
print(content)
以上就是Python中获取互联网内容的两种常用方法。urllib.request.urlopen()函数是Python标准库中的内置函数,而requests.get()函数则需要安装第三方库requests,两者都可以实现从互联网上获取最新内容的功能,具体选择哪种方法取决于个人喜好和实际需求。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11