python中tuple函数的作用

Python中的tuple函数用于创建一个不可变序列,可以包含任意类型的元素。
Python中的元组(tuple)是一种不可变的序列类型,用于存储多个元素,与列表(list)类似,但元组一旦创建就不能被修改,元组的创建和操作是Python中的基本概念之一,下面将详细介绍元组的用法。
1、创建元组
要创建一个元组,可以使用圆括号()将元素括起来,并用逗号,分隔各个元素。
my_tuple = (1, 2, 3)
也可以不使用圆括号,直接用逗号分隔元素:
my_tuple = 1, 2, 3
2、访问元组元素
可以通过索引来访问元组中的元素,索引从0开始,依次递增。
my_tuple = (1, 2, 3) print(my_tuple[0]) 输出: 1 print(my_tuple[1]) 输出: 2 print(my_tuple[2]) 输出: 3
3、元组的长度
可以使用len()函数来获取元组的长度,即元素的个数。
my_tuple = (1, 2, 3) print(len(my_tuple)) 输出: 3
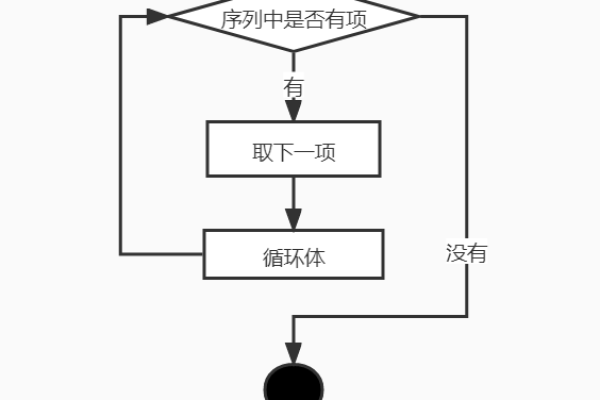
4、遍历元组
可以使用for循环来遍历元组中的元素。
my_tuple = (1, 2, 3)
for item in my_tuple:
print(item) 5、元组切片
可以使用切片操作来获取元组的子序列,切片操作返回一个新的元组,包含指定范围内的元素。
my_tuple = (1, 2, 3, 4, 5) print(my_tuple[1:4]) 输出: (2, 3, 4)
6、元组拼接
可以使用+运算符来拼接两个或多个元组。
tuple1 = (1, 2, 3) tuple2 = (4, 5, 6) print(tuple1 + tuple2) 输出: (1, 2, 3, 4, 5, 6)
7、元组重复
可以使用*运算符来重复元组的元素。
my_tuple = (1, 2, 3)
print(my_tuple 2) 输出 (1, 2, 3, 1, 2, 3) 8、元组内置方法
元组提供了一些内置方法,用于处理元组中的元素,常用的方法包括:
count(value): 返回元组中指定元素出现的次数。
index(value): 返回元组中指定元素的索引,如果元素不存在,则抛出异常。
9、元组和列表的区别
元组和列表都是用于存储多个元素的序列类型,但它们有一些重要的区别:
元组是不可变的,而列表是可变的,这意味着元组一旦创建就不能被修改,而列表可以随时添加、删除或修改元素。
元组通常用于存储固定不变的数据,例如常量或函数的参数,列表则更适用于需要动态修改数据的情况。
相关问题与解答:
1、如何创建一个空元组?
答:创建一个空元组需要使用一个特殊的语法,即两个逗号(),。empty_tuple = ()。
2、如何将列表转换为元组?
答:可以使用内置函数tuple()将列表转换为元组。my_list = [1, 2, 3]; my_tuple = tuple(my_list)。
3、如何将元组转换为列表?
答:可以使用内置函数list()将元组转换为列表。my_tuple = (1, 2, 3); my_list = list(my_tuple)。
4、如何在元组中查找某个元素的索引?
答:可以使用元组的index()方法来查找元素的索引。my_tuple = (1, 2, 3); index = my_tuple.index(2)。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20