如何实现Spark作业高效访问MySQL数据库集群?

MySQL数据库集群方案
一、前言
在现代信息时代,数据已成为企业的重要资产,为了确保数据的高可用性、可靠性和可扩展性,数据库集群技术被广泛应用,MySQL作为全球流行的开源关系型数据库管理系统,其集群方案能够提供高可用性、负载均衡和数据冗余等功能,是企业关键业务系统的理想选择,本文将详细探讨MySQL数据库集群的几种常见方案及其实现方法。
二、前提条件
1. 硬件要求
服务器:多台服务器,配置根据具体需求而定,但通常需要至少有三台服务器来实现高可用性。
存储设备:共享存储(如SAN、NAS)或独立磁盘。
网络设备:千兆以太网交换机,用于高速数据通信。
2. 软件要求
操作系统:Linux(CentOS、Ubuntu等)。
MySQL版本:建议使用MySQL 5.7及以上版本。
Percona XtraBackup、Galera Cluster等工具。
监控工具:如Prometheus、Grafana等。
三、MySQL数据库集群方案
1. 主从复制
1.1 概念
主从复制是一种常见的MySQL集群方案,通过将数据从主服务器(Master)复制到多个从服务器(Slave),以实现数据冗余和读写分离,主从复制可以是异步的,也可以是半同步的。
1.2 优点
实现数据冗余,提高数据安全性。
可以通过读写分离提高系统的并发处理能力。
故障恢复简单,手动切换即可。
1.3 缺点
异步复制可能导致数据延迟。
写操作集中在主服务器,可能成为性能瓶颈。
需要手动干预故障转移。
1.4 实施步骤
配置主服务器:
[mysqld]
logbin=mysqlbin
serverid=1
在my.cnf文件中配置日志和服务器ID,并重启MySQL服务。
创建复制用户:
CREATE USER 'replica'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%';
FLUSH PRIVILEGES;
锁定主服务器并获取二进制日志文件位置:
FLUSH TABLES WITH READ LOCK;
SHOW MASTER STATUSG
配置从服务器:
在my.cnf中配置:

[mysqld]
serverid=2
relaylog=relaybin
导入主服务器的二进制日志:
CHANGE MASTER TO
MASTER_HOST='主服务器IP',
MASTER_USER='replica',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='mysqlbin.000001',
MASTER_LOG_POS=120;
START SLAVE;
2. 双主复制(双向复制)
2.1 概念
双主复制是指两台MySQL服务器互为主从,任何一台服务器的数据变更都会同步到另一台服务器,这种模式可以提高系统的可用性和并发处理能力。
2.2 优点
高可用性,任何一个节点宕机,另一个节点仍然可以提供服务。
读写分离,提高系统并发处理能力。
2.3 缺点
配置和管理复杂,容易出现数据冲突。
需要解决数据一致性问题,通常使用GTID(全局事务标识符)。
2.4 实施步骤
配置服务器A和B:
在my.cnf中配置:
[mysqld]
logbin=mysqlbin
serverid=1
gtid_mode=ON
enforce_gtid_consistency=ON
创建复制用户并获取GTID:
CREATE USER 'replica'@'%' IDENTIFIED BY 'password';
GRANT REPLICATION SLAVE ON *.* TO 'replica'@'%';
FLUSH PRIVILEGES;
启动复制并验证:
INSTALL PLUGIN mysql_gtid_replication_plugin;
START GTID_REPLICATION;
SHOW GLOBAL VARIABLES LIKE 'gt%';
3. Galera Cluster(多主复制)
3.1 概念
Galera Cluster是一种多主复制的集群解决方案,允许所有节点同时处理读写请求,并提供强一致性保证,它基于认证的Paxos协议,确保数据的一致性和高可用性。
3.2 优点

高可用性和高容错性,任何节点宕机都不会影响整个集群的服务。
真正的多主复制,所有节点都可以处理读写请求。
强一致性保证,所有事务在所有节点上同步提交。
3.3 缺点
配置和管理复杂,需要熟悉Galera的工作原理和配置。
对网络要求较高,所有节点需要高速稳定的网络连接。
3.4 实施步骤
安装Galera库和插件:
DEBIAN_FRONTEND=noninteractive aptget install y galera mariadbserver10.1 mariadbclient10.1 mariadbcommon10.1 socat rsync
配置Galera Cluster:
在my.cnf中添加:
[galera]
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://seed1,seed2"
wsrep_cluster_name="my_galera_cluster"
wsrep_sst_method=rsync
wsrep_node_address="节点地址"
wsrep_node_name="节点名"
wsrep_bootstrap=ON
启动节点并验证集群状态:
systemctl start mariadb
systemctl enable mariadb
mysqladmin user=root password=root P | grep "wsrep"
4. Percona XtraDB Cluster
4.1 概念
Percona XtraDB Cluster是一种集成了Galera Cluster的完整集群解决方案,提供高可用性、自动故障转移和数据分片支持,适用于大规模分布式环境。
4.2 优点
高可用性和自动故障转移。
支持数据分片,适合大规模数据管理。
提供丰富的管理和监控工具。
4.3 缺点

部署和维护复杂,需要专业知识。
对硬件资源要求较高,可能需要大量的存储和计算资源。
4.4 实施步骤
安装Percona XtraDB Cluster:
yum install perconaxtradbcluster80 y
配置和初始化集群:
# 配置第一个节点
systemctl enable mysql@bootstrap.service
systemctl start mysql@bootstrap.service
# 添加其他节点到集群
systemctl enable mysql@seednodes.service
systemctl start mysql@seednodes.service
验证集群状态:
systemctl status mysql@seednodes.service
mysql u root p e "SHOW STATUS LIKE 'wsrep%';"
四、Spark作业访问MySQL数据库的方案
1. 通过JDBC直接访问MySQL数据库
1.1 基本概念:利用Spark的JDBC API,可以直接从Spark作业中读取和写入MySQL数据库,这种方式适用于简单的数据读取和写入操作。
1.2 实施步骤:
添加依赖:在项目的pom.xml中添加MySQL JDBC驱动依赖。
<dependency>
<groupId>mysql</groupId>
<artifactId>mysqlconnectorjava</artifactId>
<version8.0.30</version>
</dependency>
编写Spark作业:使用SparkContext或SparkSession读取和写入MySQL数据,示例如下:
val jdbcDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/testdb")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("dbtable", "test")
.option("user", "root")
.option("password", "root")
.load()
jdbcDF.show()
写入数据:将DataFrame数据写入MySQL表。
df.write
.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/testdb")
.option("user", "root")
.option("password", "root")
.option("truncate", "true")
.mode("append")
.save()
1.3 优点与缺点:优点是简单直接,易于实现;缺点是性能受限于JDBC驱动,不适合大规模数据操作。
2. 使用CDM(Cloudera DataMigrator)进行数据迁移和实时同步
2.1 基本概念:CDM是一个数据迁移工具,可以在不同数据源之间进行数据迁移和实时同步,适用于跨数据中心的大规模数据迁移和同步。
2.2 实施步骤:安装CDM并配置数据迁移任务,详情请参考官方文档。
2.3 优点与缺点:优点是支持多种数据源和目标,支持增量同步;缺点是配置复杂,学习和使用成本较高。
随着数据量的不断增长和企业需求的不断变化,MySQL数据库集群技术也在不断发展和完善,随着云计算和大数据技术的进一步融合,MySQL集群将在自动化、智能化和高性能方面取得更大的突破,企业应根据自身业务需求和实际情况,选择合适的集群方案,构建高效、可靠和可扩展的数据管理系统。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/18761.html
相关文章
-
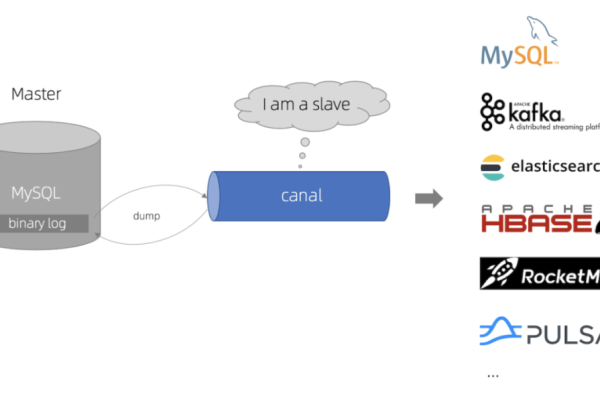
如何实现Spark作业高效访问并更新MySQL数据库?
-

如何通过Spark作业高效访问MySQL数据库?
-
如何在MySQL数据库中灵活切换数据表并成功将Spark作业结果存储,即使缺少pymysql模块,如何通过Python脚本高效访问MySQL数据库?
-
如何在MySQL数据库服务中处理Spark作业结果,并在缺少pymysql模块的情况下使用Python脚本访问MySQL数据库?
-
如何设置MySQL访问数据库的权限以及Spark作业访问MySQL数据库的方案是什么?
-
如何在缺少pymysql模块的情况下使用Python脚本访问MySQL数据库以存储Spark作业结果?
-
如何在Python脚本中访问MySQL数据库以存储Spark作业结果,当缺少pymysql模块时?
-
在缺少pymysql模块的情况下,如何使用Python脚本访问MySQL数据库以存储Spark作业结果?
