

上一篇
Cassandra的数据模型是什么
Cassandra的数据模型基于分布式架构,采用宽列存储方式,支持高并发、高可用和线性扩展。
Cassandra的数据模型是基于列的分布式数据库,它提供了高度可扩展、高性能和高可用性的数据存储解决方案,下面是关于Cassandra数据模型的详细解释:
1. 表(Table)
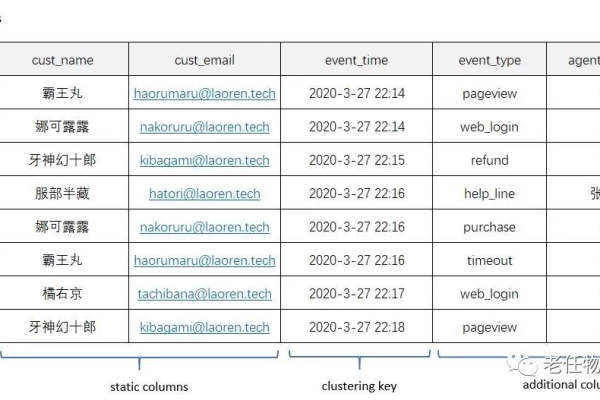
在Cassandra中,表是数据存储的基本单位,一个表由多个行(Row)组成,每个行包含一组列(Column),与传统的关系型数据库不同,Cassandra的表不需要预定义列结构,可以在运行时动态添加或删除列。
2. 行(Row)
行是Cassandra表中的一条记录,类似于关系型数据库中的行概念,每行都由一个唯一的行键(Row Key)标识,用于定位和检索数据。
3. 列(Column)
列是Cassandra表中的最小数据单元,每个列由列名(Column Name)、列值(Column Value)和时间戳(Timestamp)组成,列可以动态地添加到表中,也可以从表中删除,而无需重新定义表结构。
4. 列族(Column Family)
列族是一组相关的列的集合,它们共享相同的数据类型和访问模式,每个列族在物理上被存储在一起,以提高数据访问的性能。
5. 超级列(Super Column)
超级列是Cassandra中的一个高级特性,它将一组列组织成一个更大的结构,超级列允许更复杂的数据模型,例如嵌套的数据结构。
6. 复合主键(Composite Key)
复合主键是由多个列组成的唯一标识符,用于定位和检索特定的行,复合主键可以包含多个列,每个列都可以作为搜索条件。
7. 分区键(Partition Key)
分区键是用于将数据分布在不同节点上的键,它决定了数据在集群中的物理位置,并确保相同分区键的数据位于同一节点上,以实现高效的数据访问和查询。
8. 聚簇列(Clustering Column)
聚簇列用于在同一分区内对行进行排序和组织,它们定义了行在分区内的顺序,并允许按照聚簇列进行范围查询。
相关问题与解答
问题1: Cassandra的数据模型与传统的关系型数据库有何不同?
答:Cassandra的数据模型基于列而不是基于行,这使得它能够灵活地处理大规模的数据,与传统的关系型数据库相比,Cassandra不需要预定义列结构,可以动态地添加或删除列,Cassandra还支持分布式数据存储和弹性扩展,使其适用于大数据场景。
问题2: Cassandra中的复合主键是如何工作的?
答:复合主键是由多个列组成的唯一标识符,用于定位和检索特定的行,在复合主键中,第一个列通常是分区键,用于确定数据的物理位置,其余的列是聚簇列,用于在同一分区内对行进行排序和组织,通过使用复合主键,Cassandra可以实现更灵活的数据访问和查询方式。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/184088.html
相关文章
-

Canvans 似乎是一个拼写错误,可能您想表达的是 Canvas(画布)或 Canva(一个在线设计平台)。鉴于信息的不明确性,我将为两种情况都生成一个原创的疑问句标题。,如果指的是 Canvas(画布),,探索无限可能,画布艺术如何影响现代创作?,如果指的是 Canva(一个在线设计平台),,设计革命者,Canva如何改变我们的视觉沟通方式?
-
大数据模型创建_数据模型
-
Cassandra的数据修复是如何进行的
-
Cassandra的数据压缩是如何工作的
-
Cassandra的数据一致性怎么保证
-

randn 这个词或短语在没有上下文的情况下很难理解,因为它不是一个标准的英语单词或缩写。如果这是某种特定领域的术语或者是一个错误拼写的词,请提供更多的信息以便生成一个恰当的疑问句标题。,不过,如果 randn 是指随机数(random number)的缩写或误写,我可以提供一个基于这个假设的原创疑问句标题,,探索随机性的奥秘,randn函数是如何工作的?,请注意,如果您有具体的上下文或者 randn 指的是某个具体的概念、事件或产品,请提供详细信息,以便我能够给出一个更加精确和相关的标题。
-

Cassandra的主要限制是什么
-
Cassandra的安全性机制是什么








