

上一篇
cassandra 时序数据
Cassandra是一个分布式NoSQL数据库,特别适用于存储大量时序数据。它提供高可用性和可扩展性,支持快速写入和查询操作,适合处理时间序列数据。
Cassandra是一个高度可扩展的分布式NoSQL数据库,非常适合管理大量的时间序列数据,时间序列数据是随时间变化的数据点的集合,通常用于监控、数据分析和实时分析等场景,在Cassandra中存储和查询时间序列数据需要对数据模型进行仔细的设计,以便充分利用Cassandra的优势。
数据模型设计
为了有效地存储时间序列数据,我们通常按时间戳来分区数据,并使用合适的时间戳作为行键,如果我们正在监控传感器数据,每个传感器的读数可以按照其采集时间进行排序。
选择合理的分区键
对于时间序列数据,一个常见的做法是使用时间戳作为分区键,Cassandra允许定义分区键,它将数据分布在整个集群中,通过将时间(例如年、月、日或小时)作为分区键,我们可以确保相关的时间序列数据被存储在一起,从而提高查询效率。
使用聚簇列
聚簇列是按照声明的顺序物理存储的列,这使得范围查询非常高效,在处理时间序列数据时,可以将时间戳用作聚簇列,以便于快速执行基于时间范围的查询。
存储时间序列数据
以下是一个简单的例子,展示了如何创建一个适合存储时间序列数据的Cassandra表:
CREATE TABLE sensor_data (
sensor_id text,
recorded_at timestamp,
value double,
PRIMARY KEY ((sensor_id), recorded_at)
) WITH CLUSTERING ORDER BY (recorded_at DESC);
在这个例子中,sensor_id 是分区键,而 recorded_at 是聚簇列,数据按照 sensor_id 进行分区,并且每个分区内的数据根据 recorded_at 进行排序。
查询时间序列数据
查询Cassandra中的时间序列数据时,可以利用CQL(Cassandra Query Language)的强大功能来执行各种操作。
基于时间的过滤
可以使用CQL的 WHERE 子句来过滤出特定时间段内的数据,要查询某个传感器在过去一小时内的数据,可以这样写:
SELECT * FROM sensor_data WHERE sensor_id = 'sensor1' AND recorded_at > now() hours(1);
范围查询
由于使用了聚簇列,Cassandra能够高效地执行范围查询,这对于获取特定时间段内所有传感器的数据非常有用:
SELECT * FROM sensor_data
WHERE sensor_id IN ('sensor1', 'sensor2') AND recorded_at > '2023-01-01T00:00Z' AND recorded_at < '2023-01-02T00:00Z';
优化查询性能
为了提高查询性能,可以考虑以下策略:
1、数据建模:根据查询模式调整分区键和聚簇列的选择。
2、二级索引:如果需要按非主键列进行查询,可以创建二级索引。
3、物化视图:为常用的查询模式创建物化视图,以便快速访问特定数据集。
4、分页和限制:使用 LIMIT 和 OFFSET 子句来分页查询大型数据集,防止超时和性能问题。
相关问题与解答
Q1: Cassandra中的聚簇列和普通列有什么区别?
A1: 聚簇列按照表的聚簇顺序物理存储,这使得范围查询更加高效;而普通列不保证有特定的物理存储顺序。
Q2: 在Cassandra中如何实现时间序列数据的降采样?
A2: 可以在写入数据之前在应用程序层实现降采样逻辑,或者使用Cassandra提供的窗口函数在查询时进行降采样。
Q3: Cassandra支持哪些类型的时间序列数据查询?
A3: Cassandra支持基于分区键和聚簇列的范围查询、过滤查询以及使用二级索引的查询。
Q4: 如何在Cassandra中实现多时区的时间序列数据处理?
A4: 可以将时间戳存储为UTC时间,并在应用程序层进行时区转换,这样可以保持数据的一致性,同时简化数据库的设计。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/183765.html
相关文章
-

Canvans 似乎是一个拼写错误,可能您想表达的是 Canvas(画布)或 Canva(一个在线设计平台)。鉴于信息的不明确性,我将为两种情况都生成一个原创的疑问句标题。,如果指的是 Canvas(画布),,探索无限可能,画布艺术如何影响现代创作?,如果指的是 Canva(一个在线设计平台),,设计革命者,Canva如何改变我们的视觉沟通方式?
-

randn 这个词或短语在没有上下文的情况下很难理解,因为它不是一个标准的英语单词或缩写。如果这是某种特定领域的术语或者是一个错误拼写的词,请提供更多的信息以便生成一个恰当的疑问句标题。,不过,如果 randn 是指随机数(random number)的缩写或误写,我可以提供一个基于这个假设的原创疑问句标题,,探索随机性的奥秘,randn函数是如何工作的?,请注意,如果您有具体的上下文或者 randn 指的是某个具体的概念、事件或产品,请提供详细信息,以便我能够给出一个更加精确和相关的标题。
-
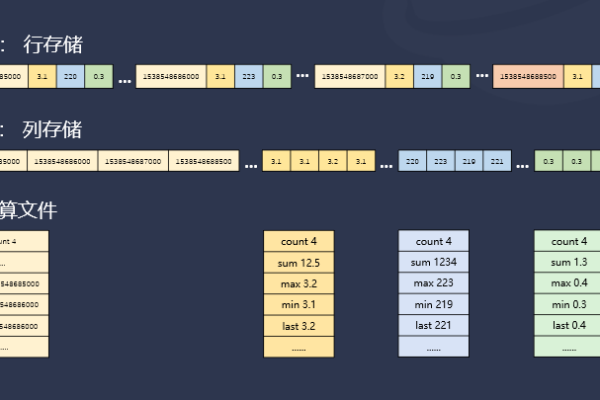
行情服务器时序数据库属于哪种类型的数据库?
-
aapt 在文章中通常指代 Android Asset Packaging Tool,这是一个用于Android应用打包的工具。假设文章讨论了该工具的使用、功能、优势或更新等相关内容,以下是一个可能的原创疑问句标题,,如何有效利用aapt优化Android应用的性能和资源管理?
-
如何利用MySQL快速创建时序数据库表?
-
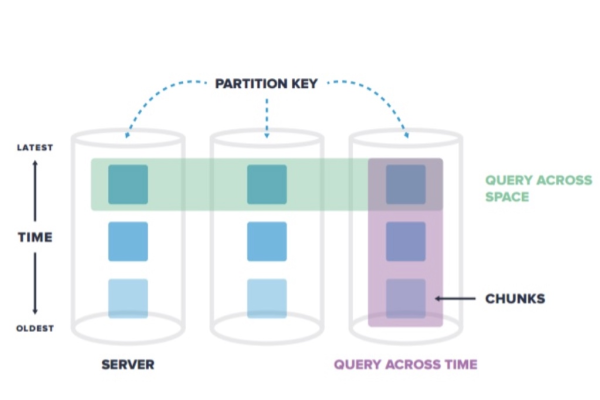
行情服务器使用的时序数据库属于哪种类型?
-
如何利用MongoDB进行高效的时序数据分析?
-
时序数据库的作用








