卸载office2016报错

在卸载Office 2016时,可能会遇到各种报错,以下为一些常见报错及其详细解决方法。
报错0xC004F017
错误描述:产品密钥被阻止或许可证未安装。
错误原因:
1、Office的版本不对,激活客户端仅支持平台提供的相应软件版本的激活,其他版本无法激活。
2、旧版本的Office未卸载干净。
解决方案:
1、如果安装的Office不是从平台下载的,请从平台下载正确的版本进行重新安装。
2、如果之前装过其他版本的Office,在安装平台提供的Office之前请先完全卸载这些Office。
卸载方法:
1、使用Microsoft Fix it工具卸载Office套件(推荐)。
Windows 7、Windows Vista或Windows XP:使用MicrosoftEasyFix50450工具卸载Office 2010,使用o15ctrremove.diagcab工具卸载Office 2013、Office 2016、Office 365。
Windows 10、Windows 8.1或Windows 8:使用MicrosoftFixit20055工具卸载Office 2010,使用o15ctrremove.diagcab工具卸载Office 2013、Office 2016、Office 365。
2、从控制面板卸载Office套件。
报错1731
错误描述:程序包不同步。
错误原因:Office卸载不完整。
解决方案:
1、删除所有可能与Office相关的软件。
2、使用优化大师清理注册表。
3、重新安装Office。
报错1321
错误描述:安装程序无法修改文件。
解决方法:
1、打开报错信息中的文件所在文件夹。
2、右击文件夹,选择“管理员取得所有权”。
3、重新卸载Office。
其他问题
1、激活Office时遇到报错。
解决方法:
确保Windows 10系统已联网自动激活。
确保笔记本电脑有预装的正版Office 2016。
确保有一个有效的微软账号。
遵循激活步骤进行操作。
2、卸载Office时遇到其他未知错误。
解决方法:
检查是否有足够的权限进行卸载操作。
尝试使用其他卸载工具,如Revo Uninstaller等。
在安全模式下卸载Office。
重启计算机,进入Windows恢复环境,尝试卸载Office。
在卸载Office 2016时,可能会遇到各种报错,解决这些问题的关键在于了解错误原因,并采取合适的解决方案,以下是几点建议:
1、在卸载Office之前,请确保已经备份重要数据。
2、使用官方提供的卸载工具进行卸载,以确保卸载干净。
3、遇到问题时,请查阅官方文档或寻求技术支持。
4、如果报错问题无法解决,可以考虑重新安装Office,然后再次尝试卸载。
5、确保计算机系统处于良好状态,避免因系统问题导致卸载失败。
希望以上内容对解决卸载Office 2016报错问题有所帮助,在遇到具体问题时,可根据实际情况选择合适的解决方案,祝您操作顺利!
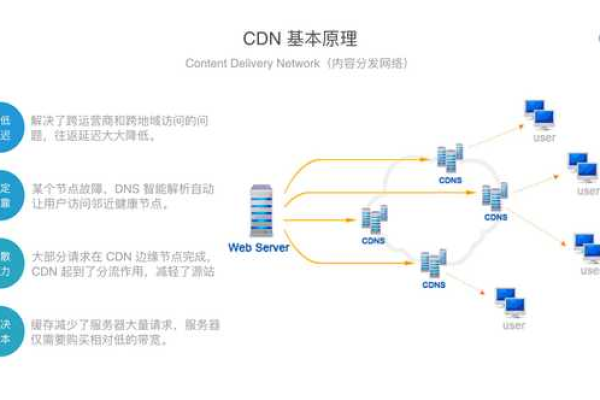


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22