怎么解决香港服务器卡顿问题

解决香港服务器卡顿问题
概述:
香港的服务器卡顿问题可能会影响网站、应用程序或服务的用户体验,卡顿可能是由于多种原因造成的,包括硬件资源不足、网络连接问题、软件配置错误等,以下是一些详细的步骤和建议,用于诊断和解决服务器卡顿的问题。
监控服务器性能
要解决卡顿问题,首先需要了解服务器当前的性能状况,使用以下工具和方法来监控服务器:
工具与方法:
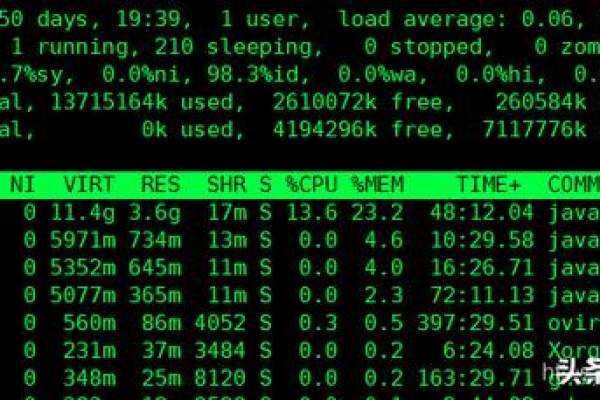
系统监控工具:如Nagios、Zabbix、或云服务提供商的内置监控服务。
资源使用情况分析:检查CPU使用率、内存使用量、磁盘I/O以及网络流量。
日志文件审查:查看系统日志和应用日志,寻找错误或异常信息。
优化服务器配置
根据监控数据,调整服务器配置以提高效率。
1. 硬件资源升级
如果资源监控显示硬件资源紧张,考虑升级服务器硬件,如增加内存、更换更快的处理器或使用SSD硬盘。
2. 负载均衡
使用负载均衡器分散流量到多台服务器,减轻单台服务器的压力。
3. 数据库优化
对数据库进行性能调优,比如索引优化、查询优化和适当的缓存策略。
网络优化
网络延迟或丢包可能是导致卡顿的原因之一。
1. 带宽升级
如果监控发现网络带宽饱和,联系服务提供商升级带宽。
2. 优化路由路径
与互联网服务提供商(ISP)合作,优化路由路径减少延迟。
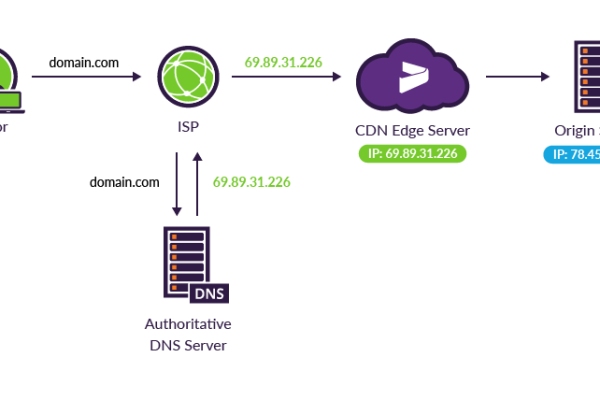
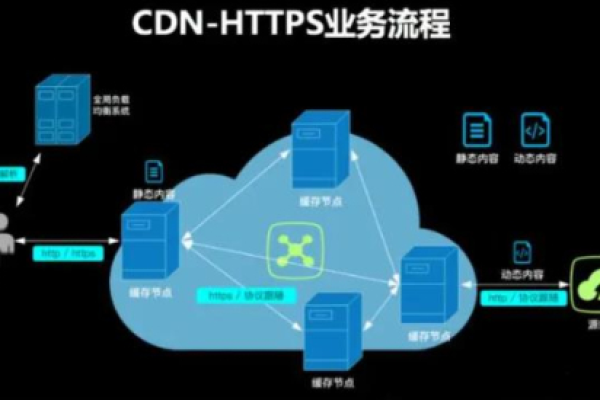
3. CDN使用
使用内容分发网络(CDN)将内容缓存至离用户更近的地理位置,加快访问速度。
软件和服务优化
确保运行在服务器上的软件和服务配置得当。
1. 应用程序代码优化
对代码进行性能分析和优化,修复可能的性能瓶颈。
2. 服务配置调整
根据最佳实践调整服务(如Web服务器、数据库服务器)的配置。
3. 更新和打补丁
定期更新服务器上的软件,安装最新的安全补丁和性能改进。
实施预防措施
采取预防性措施避免未来的卡顿问题。
1. 定期维护计划
制定并执行定期的服务器维护计划。
2. 灾难恢复计划
准备并测试灾难恢复计划以防不可预测的事件。
3. 用户培训
教育用户如何高效地使用系统资源,减少不必要的负载。
通过上述步骤,您可以系统地诊断并解决香港服务器卡顿的问题,记得持续监控服务器性能,并根据反馈不断调整优化策略。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01