小程序云服务器部署怎么设置

小程序云服务器部署设置
在互联网技术快速发展的今天,小程序因其便捷性和广泛的用户基础成为众多开发者和企业的首选,而云服务器作为支撑小程序运行的后端环境,其部署设置对于小程序的性能和稳定性至关重要,以下是小程序云服务器部署的详细步骤和要点。
准备工作
在开始部署之前,需要准备以下几项:
1、选择一个可靠的云服务提供商,如腾讯云、阿里云等。
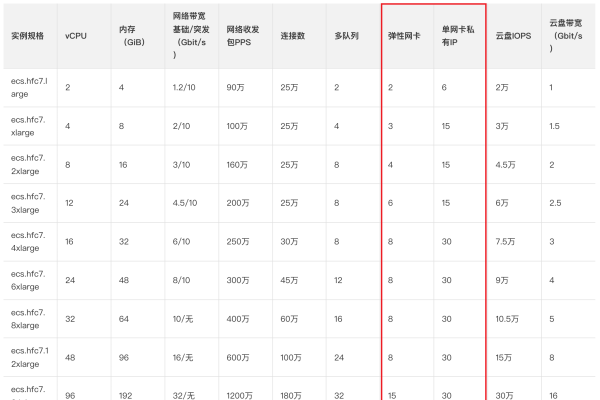
2、购买云服务器,选择合适的配置(CPU、内存、存储空间等)。
3、确定操作系统,通常选择Linux或Windows Server。
4、准备小程序所需的后端环境,如Node.js、PHP、数据库等。
5、准备小程序代码和相关资源文件。
环境配置
系统初始化
1、登录云服务器,进行系统初始化设置。
2、更新系统软件包,确保所有组件都是最新的。
3、安装网络防火墙,配置安全规则。
后端环境搭建
1、根据小程序需求安装相应的后端运行环境,例如Node.js或PHP。
2、安装数据库服务,如MySQL或MongoDB,并创建数据库和表。
3、配置环境变量,确保后端服务能够正确运行。
依赖安装
1、根据小程序后端代码的依赖要求,安装必要的软件包和库。
2、使用包管理工具(如npm、yum等)安装依赖。
代码部署
1、将小程序代码上传到云服务器。
2、配置代码仓库,如Git,以便于版本控制和多人协作。
3、设置定时任务,如数据备份、自动更新等。
安全设置
1、配置SSL证书,启用HTTPS以保障数据传输的安全。
2、定期检查系统破绽,及时打补丁。
3、设置强密码策略,防止非规访问。
性能优化
1、根据访问量调整服务器配置,保证响应速度。
2、使用缓存技术,如Redis,减少数据库压力。
3、开启Gzip压缩,减少网络传输数据量。
监控与维护
1、配置监控系统,实时监控服务器状态。
2、定期检查日志,分析系统运行情况。
3、制定应急计划,处理突发事件。
相关问答FAQs
Q1: 如何选择合适的云服务器配置?
A1: 选择合适的云服务器配置需要考虑小程序的用户规模、功能复杂度和预期流量,可以从中等配置开始,随着业务的发展逐步升级,要考虑成本和性能的平衡,避免资源浪费。
Q2: 小程序云服务器部署后如何进行扩展?
A2: 当小程序用户量增加或业务发展需要更多资源时,可以通过云服务提供商的弹性伸缩服务来增加服务器实例,可以优化代码和数据库查询,使用负载均衡和分布式计算等技术来提高系统的处理能力。
通过以上步骤和要点,可以确保小程序在云服务器上的顺利部署和稳定运行,需要注意的是,云服务器的部署和管理是一个持续的过程,需要根据实际情况不断调整和优化。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20