如何利用PyCharm进行有效的代码检查?

在现代软件开发中,IDE扮演着至关重要的角色,作为智能的编程环境,IDE提供了代码编写、调试和管理的一体化解决方案,PyCharm作为一个功能强大的Python IDE,通过其内置的代码检查工具Inspect Code和对第三方工具如Pylint的支持,大大提升了代码质量和开发效率,本文将深入探讨PyCharm的代码检查功能及其配置方法,以及如何利用这些工具来提升代码的规范性和可维护性,具体分析如下:
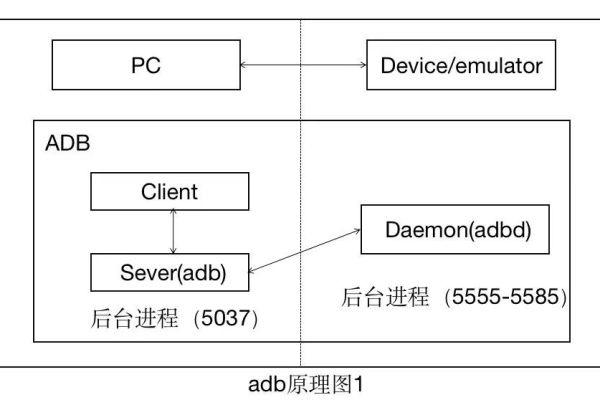
1、主要功能
Inspect Code的功能:Inspect Code是PyCharm的一项核心功能,它提供静态代码审查,能够检测出语法错误、不符合PEP8编码规范的问题,并提出修复建议。
PEP8编码规范:PEP8是Python社区公认的编码规范,旨在提高代码的可读性和一致性,PyCharm不仅检查代码是否遵守PEP8,还提供了自动格式化功能来帮助开发者修正不符合规范的代码。
集成Pylint:Pylint是一个强大的第三方代码检查工具,它可以集成到PyCharm中,提供更为严格的代码审查,确保所有代码均符合PEP8规范,从而促进良好编程习惯的培养。
2、配置方法
启用Inspect Code:在PyCharm中启用Inspect Code非常简单,用户只需在需要检查的文件夹或文件上点击右键,选择“Inspect Code”即可启动代码审查界面。
配置Pylint:为使用Pylint,需要先在系统中安装Pylint,然后在PyCharm的设置中找到Python Integrated Tools,设置Pylint的路径,并按需配置相关参数。
3、运行方式

Inspect Code操作界面:Inspect Code的操作界面分为两部分:左侧列出了审查结果,右侧则是操作界面,用户可以在这里清晰地看到每一处问题,并通过点击相应的按钮进行自动格式化或修复代码。
实时代码检查:PyCharm还支持实时代码检查,编写代码时即时显示可能的错误或不符合规范的地方,这有助于即时纠正问题,保持代码质量。
4、与第三方工具的集成
整合Pylint提高标准:通过将Pylint整合进PyCharm,开发者可以享受到更全面的代码审查,Pylint会按照PEP8规范对代码进行严格检查,并提供详细的改进建议。
自定义检查规则:PyCharm允许用户自定义代码检查的规则,可以根据项目需求添加特定的检查项或调整检查的严格程度。
5、提高代码质量
自动化修复功能:PyCharm不仅仅是发现代码中的问题,它还提供了自动化的修复功能,如自动格式化代码以符合PEP8规范,极大提高了代码的一致性和可维护性。

教育性反馈:通过代码检查工具提供的反馈,开发者可以不断学习和理解Python的最佳实践,从而提高自身的编程技能。
6、编程效率的提升
即时错误发现:PyCharm的实时检查功能使得开发者在编码过程中就能发现并修正错误,减少了后期调试的时间和成本。
批量处理问题:利用Inspect Code的批量审查功能,开发者可以一次性检查整个项目,快速定位并解决多个问题点,大幅提升开发效率。
PyCharm通过其Inspect Code功能及对Pylint等第三方工具的支持,为Python开发者提供了一个全面、高效的代码检查和审查环境,正确配置和使用这些工具不仅可以提升代码质量,遵循PEP8规范,也培养了良好的编程习惯,最终提升了开发效率和代码的可维护性,接下来将通过一些常见问题的解答来进一步深化对PyCharm代码检查功能的理解和应用。
FAQs
Q1: PyCharm中的Inspect Code与Pylint有什么区别?

A1: Inspect Code是PyCharm内置的代码审查工具,侧重于发现语法错误和PEP8规范问题;而Pylint是一个独立的第三方工具,提供更全面的代码检查,包括更复杂的编程规范和代码质量评估,两者可以结合使用,以获得最佳的检查效果。
Q2: 如何自定义PyCharm的Inspect Code检查规则?
A2: 在PyCharm中,可以通过“Settings”或“Preferences” > “Editor” > “Inspections”来自定义Inspect Code的检查规则,这里你可以根据个人或项目需求勾选或取消某些检查项,也可以调整各项检查的严重级别。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20