上一篇
如何解决分区倾斜问题?
解决分区倾斜问题通常涉及对数据进行重新分区或优化查询以减少特定分区的负载,以下是一些详细的解决方案:

1. 识别倾斜的分区
数据审查:通过分析数据分布,识别出哪些分区的数据量远大于其他分区。
性能监控:监控查询执行计划和时间,找出哪些分区是瓶颈。
2. 数据重分区
范围分区调整:如果使用范围分区,可以调整分区的范围,使得数据更均匀地分布在各个分区上。
列表分区调整:对于列表分区,可以通过增加或减少列表值来调整分区。
哈希分区调整:通过改变哈希函数或增加分区数量来改善数据的分布。
3. 使用分区表的连接策略
广播小表:在连接操作中,将小表广播到每个节点,避免数据倾斜。
分区键连接:确保连接键是分区键,以减少跨分区的数据移动。
4. 优化查询
过滤条件:在查询中添加过滤条件,减少需要处理的数据量。
分批处理:将大查询分解为多个小查询,分别处理,然后合并结果。
5. 使用采样和近似查询
数据采样:对数据集进行采样,以获得查询的近似结果。
近似查询处理:使用如HyperLogLog、CountMin Sketch等技术进行近似查询。
6. 应用分布式计算模式
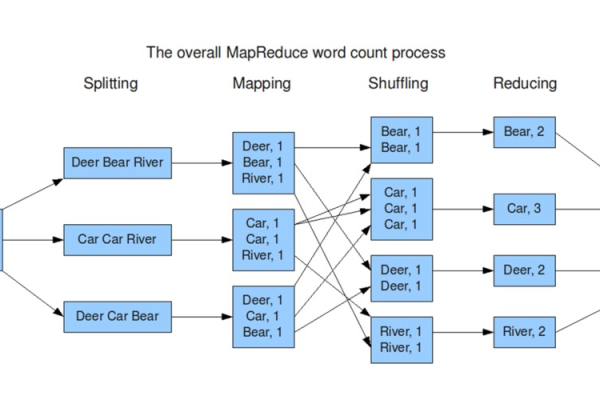
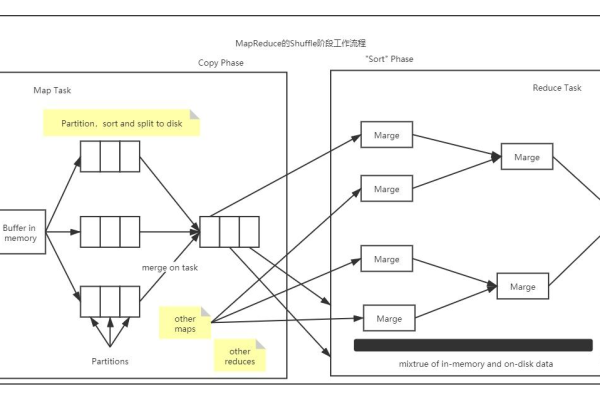
MapReduce:使用MapReduce框架,将处理逻辑推送到数据所在的节点。
Spark:利用Spark的弹性分布式数据集(RDD)和转换操作,优化数据处理流程。
7. 硬件和网络优化
增加资源:为处理大量数据的节点增加CPU、内存或I/O资源。
网络优化:优化网络配置,减少数据传输延迟。
8. 动态分区调整
动态调整策略:根据数据增长和访问模式动态调整分区策略。
自动化工具:使用自动化工具监控数据分布和查询性能,自动调整分区。
9. 数据库参数调整
并行度设置:调整数据库的并行度参数,以控制并行执行的线程数。
内存管理:优化内存分配,确保关键操作有足够的内存可用。
10. 使用第三方工具和服务
专业服务:利用数据库供应商或第三方提供的专家服务进行分区优化。
云服务:利用云计算平台提供的自动扩展和优化功能。
以上方法可以单独使用,也可以组合使用,以解决特定的分区倾斜问题,在实施这些解决方案时,应考虑数据的特性、查询的类型以及系统的性能目标。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/169610.html