如何在最新版dedecms中实现搜索模版时显示附加字段?

在最新版的DedeCMS中,实现搜索模板显示附加字段可以通过修改系统文件或利用相关插件来完成,下面将详细介绍具体的实现办法,包括所需文件的修改、相关模型的建立以及推荐插件的使用。
修改arc.searchview.class.php文件
1、定位文件与代码行
文件路径:在include文件夹下找到arc.searchview.class.php文件。
修改行数:找到681行,这是需要修改的代码行的开始。
2、修改SQL查询语句
原始代码:默认的查询语句仅选择文章(arc)的基础字段和文章类型(act)的部分字段。
:在SQL查询语句中加入额外的字段,如附加字段,确保这些字段能被搜索并显示在结果中。
3、保存与测试
保存更改:修改后需保存文件。
进行测试:通过DedeCMS的搜索功能来查看是否能正常显示新增的附加字段。
修改likearticle.lib.php文件
1、定位文件与修改目的
文件路径:修改文件位于include/taglib/likearticle.lib.php。
修改目的:默认的likearticle标签不显示自定义的附加字段,修改旨在使其支持显示这些字段。
2、调整文件代码
修改方法:具体代码修改的细节需要根据实际使用的附加字段进行调整。
验证效果:修改后,相关文章列表应能显示自定义的附加字段。
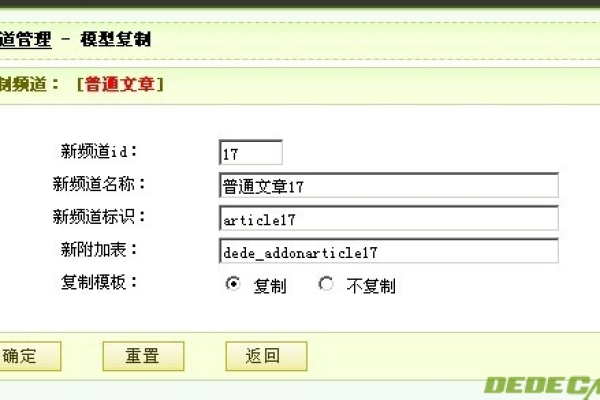
新建模型与附加表
1、创建新模型
模型名称:新建一个“商标信息”模型。
附加表:指定附加表为dede_shangbiao,其中可以包含额外的字段信息。
2、添加附加字段
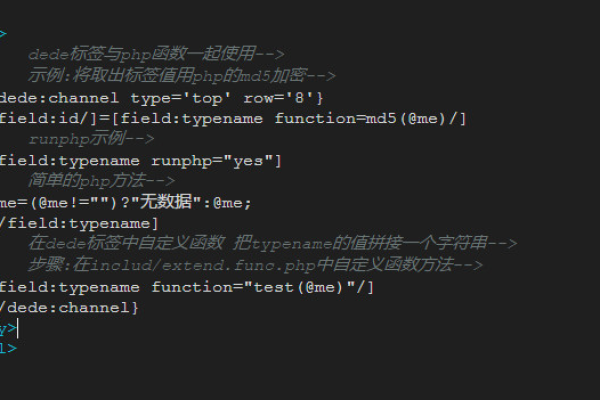
字段示例:例如添加商标ID (sbID) 和创意说明 (chuangyi) 作为附加字段。
字段配置:在模型中配置这些字段,以便在搜索时能够被索引和检索。
3、整合到搜索模板
模板修改:在通用模板head.htm中进行修改,以整合新模型的搜索功能。
前端显示:确保在搜索结果中能够看到来自新模型的附加字段信息。
使用推荐的DedeCMS搜索插件
1、ZSearch插件
功能特点:支持全文搜索、搜索结果高亮等。
安装配置:可根据插件提供的指南进行安装和配置。
2、DedeSearch插件
易用性:简单易用的搜索插件,提供精准的搜索结果。
选择理由:如果默认的搜索功能不能满足需求,可以考虑使用此类插件改进搜索体验。
为了更全面地理解和应用上述修改,以下是一些应该考虑的附加因素和注意事项:
确保在进行任何文件修改前备份原始文件,以防万一需要恢复。
修改系统文件可能影响DedeCMS的核心功能,因此建议在非生产环境下先进行测试。
对于系统版本的更新,修改过的文件可能需要重新调整以适应新版本的变化。
考虑到DedeCMS的安全性,使用插件时确保来源可靠,避免使用未经验证的第三方插件。
如有编程基础,可以考虑定制开发适用于特定需求的搜索功能,提高灵活性和功能性。
在最新版的DedeCMS中实现搜索模板显示附加字段主要涉及对系统文件的修改和模型的创新配置,虽然这一过程可能需要一定的技术知识,但通过细致地遵循上述步骤,大多数用户应能成功实现,考虑到安全性和稳定性,使用官方推荐或社区广泛认可的插件是一个简易而有效的替代方案,无论哪种方法,都要确保充分测试并做好数据备份,以免不测情况导致数据丢失或网站功能异常。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01